Measurements in marketing research. Types of scales used in semantic differential Semantic differential scale example
The presence of contradictory judgments in the answers on scale B leads to the need to consider the scale unacceptable.
This approach to increasing the reliability of a scale is very complex. Therefore, it can only be recommended when developing critical tests or techniques intended for mass use or panel studies.
It is possible to test one method on several respondents. If the method is reliable, then different respondents will give consistent information, but if their results are poorly consistent, then either the measurements are unreliable or the results of individual respondents cannot be considered equivalent. In the latter case, it is necessary to determine whether any group of results can be considered more trustworthy. The solution to this problem is all the more important if it is assumed that it is equally permissible to obtain information by any of the methods under consideration.
The use of parallel methods for measuring the same property faces a number of difficulties.
Firstly, it is unclear to what extent both methods measure the same quality of the object, and, as a rule, there are no formal criteria for testing such a hypothesis. Consequently, it is necessary to resort to a substantive (logical-theoretical) justification of a particular method.
Second, if parallel procedures are found to measure a common property (the data do not differ significantly), the question remains about the theoretical justification for using these procedures.
It must be admitted that the very principle of using parallel procedures turns out to be not a formal, but rather a substantive principle, the application of which is very difficult to substantiate theoretically.
One of the widespread approaches to establishing validity is the use of so-called judges, experts. Researchers ask a specific group of people to act as competent individuals. They are offered a set of features intended to measure the object being studied, and are asked to evaluate the correctness of attributing each of the features to this object. Joint processing of judges' opinions will make it possible to assign weights to features or, what is the same, scale ratings in the measurement of the object being studied. A set of features can be a list of individual judgments, characteristics of an object, etc.
Judging procedures are varied. They may be based on methods of paired comparisons, ranking, sequential intervals, etc.
The question of who should be considered judges is quite controversial. Judges selected as representatives of the population being studied must, in one way or another, represent its micromodel: according to the judges’ assessments, the researcher determines how adequately certain points of the survey procedure will be interpreted by respondents.
However, when selecting judges, a difficult question arises: what is the influence of the judges’ own attitudes on their assessments, because these attitudes may differ significantly from the attitudes of the subjects in relation to the same object.
In general, the solution to the problem is to: a) carefully analyze the composition of judges from the point of view of the adequacy of their life experience and signs of social status to the corresponding indicators of the surveyed population; b) identify the effect of individual deviations in judges' scores relative to the overall distribution of scores. Finally, it is necessary to evaluate not only the quality, but also the size of the sample population of judges.
On the one hand, this number is determined by consistency: if the consistency of judges' opinions is sufficiently high and, accordingly, the measurement error is small, the number of judges can be small. It is necessary to set the value of the permissible error and, based on it, calculate the required sample size.
If complete uncertainty of the object is detected, i.e. in the case when the opinions of the judges are distributed evenly across all assessment categories, no increase in the size of the sample of judges will save the situation and will not bring the object out of the state of uncertainty.
If the object is sufficiently uncertain, then a large number of gradations will only introduce additional interference into the work of judges and will not provide more accurate information. It is necessary to identify the stability of judges' opinions using repeated testing and, accordingly, narrow the number of gradations.
The choice of a particular method, method or technique for checking validity depends on many circumstances.
First of all, it should be clearly established whether any significant deviations from the planned measurement program are possible. If the research program sets strict limits, not one, but several methods should be used to check the validity of the data.
Secondly, it must be kept in mind that the levels of robustness and validity of data are closely interrelated. Unstable information, due to its lack of reliability according to this criterion, does not require too strict verification of validity. Sufficient robustness should be ensured, and then appropriate steps should be taken to clarify the boundaries of interpretation of the data (i.e., identify the level of validity).
Numerous experiments to identify the level of reliability allow us to conclude that in the process of developing measurement instruments, in terms of their reliability, the following sequence of main stages of work is advisable:
a) Preliminary control of the validity of methods for measuring primary data at the stage of testing the methodology. Here it is checked to what extent the information meets its intended purpose in essence and what are the limits of subsequent interpretation of the data. For this purpose, small samples of 10–20 observations are sufficient, followed by adjustments to the structure of the methodology.
b) The second stage is piloting the methodology and thoroughly checking the stability of the initial data, especially the selected indicators and scales. At this stage, a sample is needed that represents a micromodel of the real population of respondents.
c) During the same general aerobatics, all necessary operations related to checking the level of validity are carried out. The results of the analysis of pilot data lead to the improvement of the methodology, to the refinement of all its details and, ultimately, to the receipt of the final version of the methodology for the main study.
d) At the beginning of the main study, it is advisable to check the stability of the method used in order to calculate accurate indicators of its stability. Subsequent clarification of the boundaries of validity goes through the entire analysis of the results of the study itself.
Regardless of the reliability assessment method used, the researcher has four sequential steps to improve the reliability of the measurement results.
First, when measurement reliability is extremely low, some questions are simply discarded from the questionnaire, especially when the degree of reliability can be determined during the questionnaire development process.
Secondly, the researcher can “collapse” the scales and use fewer gradations. Let's say, the Likert scale in this case can only include the following gradations: “agree”, “disagree”, “I have no opinion”. This is usually done when the first step has been completed and when the examination has already been carried out.
Third, as an alternative to the second step or as an approach carried out after the second step, reliability assessment is carried out on a case-by-case basis. Let's say a direct comparison is made of respondents' answers during their initial and retests or with some equivalent answer. Answers from unreliable respondents are simply not taken into account in the final analysis. Obviously, if you use this approach without an objective assessment of the respondents’ reliability, then by throwing out “undesirable” answers, the research results can be adjusted to the desired ones.
Finally, after the first three steps have been used, the level of reliability of the measurements can be assessed. Typically, measurement reliability is characterized by a coefficient varying from zero to one, where one characterizes maximum reliability.
It is usually considered that the minimum acceptable level of reliability is characterized by numbers of 0.65–0.70, especially if the measurements were carried out for the first time.
It is obvious that in the process of various and numerous marketing research carried out by different companies, there was a consistent adaptation of measurement scales and methods of their implementation to the goals and objectives of specific marketing research. This makes it easier to solve the problems discussed in this section, and makes it rather necessary when conducting original marketing research.
The validity of measurements characterizes completely different aspects than the reliability of measurements. A measurement may be reliable but not valid. The latter characterizes the accuracy of measurements in relation to what exists in reality. For example, a respondent was asked about his annual income, which is less than $25,000. Reluctant to tell the interviewer the true figure, the respondent reported income as “more than $100,000.” When retested, he again named this figure, demonstrating a high level of reliability of the measurements. Falsehood is not the only reason for the low level of measurement reliability. You can also call it poor memory, poor knowledge of reality by the respondent, etc.
Let's consider another example that characterizes the difference between reliability and validity of measurements. Even an inaccurate watch will show the time at one hour twice a day, demonstrating high reliability. However, they can go very inaccurately, i.e. The time display will be unreliable.
The main direction of checking the reliability of measurements is to obtain information from various sources. This can be done in different ways. Here, first of all, the following should be noted.
We must strive to compose questions in such a way that their wording contributes to obtaining reliable answers. Further questions related to each other may be included in the questionnaire.
For example, the questionnaire contains a question about the extent to which the respondent likes a certain food product of a certain brand. And then it is asked how much of this product was purchased by the respondent over the last month. This question is aimed at checking the reliability of the answer to the first question.
Often two different methods or sources of information are used to assess the reliability of measurements. For example, after filling out written questionnaires, a number of respondents from the initial sample are additionally asked the same questions by telephone. Based on the similarity of the answers, the degree of their reliability is judged.
Sometimes, based on the same requirements, two samples of respondents are formed and their answers are compared to assess the degree of reliability.
Questions to check:
What is measurement?
How does objective measurement differ from subjective measurement?
Describe the four scale characteristics.
Define the four types of scales and indicate the types of information contained in each.
What are the arguments for and against using neutral gradation in a symmetrical scale?
What is a modified Likert scale and how do the life style scale and the semantic differential scale relate to it?
What is the “halo effect” and how should a researcher control it?
What components determine the content of the concept of “measurement reliability”?
What disadvantages may the measurement scale used have?
What methods for assessing measurement stability do you know?
What approaches to assessing the level of validity of measurements do you know?
How does measurement reliability differ from measurement validity?
When should a researcher evaluate the reliability and validity of a measurement?
Let's assume that you are engaged in marketing research and the owner of a private grocery store has approached you with a request to create a positive image of this store. Design a semantic differential scale to measure the relevant image dimensions of a given store. When performing this work you must do the following:
A. Conduct a brainstorming session to identify a set of measurable indicators.
b. Find the corresponding bipolar definitions.
V. Determine the number of gradations on the scale.
d. Choose a method to control the “halo effect”.
Design a measurement scale (justify the choice of scale, the number of gradations, the presence or absence of a neutral point or gradation; think about whether you are measuring what you planned to measure) for the following tasks:
A. A manufacturer of children's toys wants to know how preschoolers react to the video game “Sing with Us,” in which the child must sing along with the characters of the animated film.
b. A dairy products manufacturer is testing five new yoghurt flavors and wants to know how consumers rate the flavors in terms of sweetness, pleasantness, and richness.
List literature
Burns Alvin C., Bush Ronald F. Marketing Research. New Jersey, Prentice Hall, 1995.
Evlanov L.G. Theory and practice of decision making. M., Economics, 1984.
Eliseeva I.I., Yuzbashev M.M. General theory of statistics. M., Finance and Statistics, 1996.
A sociologist's workbook. M., Nauka, 1977.
To prepare this work, materials were used from the site http://www.marketing.spb.ru/
Current page: 4 (book has 9 pages total) [available reading passage: 7 pages]
Topic 4. SAMPLING METHOD FOR COLLECTING INFORMATION, DETERMINING THE VOLUME AND SAMPLING PROCEDURE
1. Problem situation“Research on new business prospects”
Entrepreneur I. Ivanov is considering the possibility of organizing a full-cycle advertising agency in the city of N, providing clients with almost the entire range of advertising services. In his opinion, the service will be in demand, because the consumer goods market in the city of N is promising (currently Belarusian manufacturers are actively developing it), in other words, the market capacity is quite high. Taking into account the novelty of this business, Ivanov wants to analyze the situation on the market and draw conclusions about the attractiveness of such a business.
To solve this problem, it was decided to conduct a study of the competitive situation in the market, as well as to identify market segments that should be targeted by the advertising agency.
When studying the competitive situation, the following subtasks can be identified: researching offers from competing agencies, determining the volume of supply of advertising services in the market of the city N, describing the advertising services provided, segmenting by price niches, identifying the mechanism of interaction with large corporate clients, assessing the prospects for clients moving from closest competitors, consumers' assessment of the quality of service provided by their closest competitors.
The study of the segment of large corporate clients is planned to be carried out in the following areas: identifying client needs for agency services, assessing the volume of demand for services, identifying clients’ price orientations, studying mechanisms for possible cooperation.
Questions and tasks
1. What sources of secondary information can be used to solve the problems?
2. What marketing research methods can be used in this case?
3. Who constitutes the population for the purposes of this study?
2. Problem situation “New product on the market”
A small confectionery company producing cakes has developed a new product - a dietary cake with a reduced calorie content, which it plans to supply to the market in the city of N and the region. The company's management plans to organize work in the retail segment of the city market. Moreover, the company management has information about direct competitors. It is also planned to collect information about manufacturers of substitute goods. A marketing audit showed that the company does not have an idea of the target audience, and also does not have a clear positioning strategy. To clarify these circumstances, it is planned to conduct marketing research, the main objectives of which are:
– identifying potential consumers of dietary cakes;
– identifying behavioral characteristics of target consumers (frequency of consumption, price orientations, existing health problems, people prone to consuming new products; people watching their weight);
– assessment of the potential market capacity;
– identification of direct competitors and competitors in the production of substitute goods;
– segmentation of dietary cake consumers;
– product positioning in selected market segments;
– study of possible distribution channels.
Questions and tasks
1. Determine research methods and sources of secondary information.
2. Justify sampling methods.
3. Who constitutes the population for the purposes of the study?
3. Problem situation“Testing a new label”
OJSC Pivo plans to introduce kvass with a new label to the regional market. Several Moscow advertising agencies presented developed label options, so the company's management decided to conduct marketing research in order to identify the best label option from the point of view of representatives of the target audience.
The marketing department was assigned the following tasks:
– identify consumer preferences regarding the “kvass” product (volume, shape and color of the bottle, etc.);
– assess consumer perception of the new label option;
– assess target consumers’ views on the information contained on the label.
The most preferred method of marketing research was a survey of potential consumers at points of sale.
Questions and tasks
1. What types of retail outlets need to be researched?
2. Which method of sampling retail outlets is most preferable in this situation (probabilistic or deterministic)?
3. What are the criteria for selecting respondents to participate in the survey?
4. Practical work“Determining the sampling frame”
Goal of the work: Explore methods for determining sample frame and sample size.
The content of the work: Students receive lists with research tasks. Research questions can be simple and related to products that are familiar to students, for example, how many chocolate bars does an economics student at a university consume on average per week? For this purpose, students need to construct a sampling frame (assuming that the sampling frame and the target population are identical) by filling out the table. 18.
Table 18
Hypothetical population for studying chocolate bar consumption
However, attention should be paid to the fact that maximum and minimum values should not be considered that significantly exceed the average number of bars consumed. Using a table of random numbers (Appendix 13), students need, without resorting to a survey of the entire population, to determine how many chocolate bars students at the university's Faculty of Economics consume on average per week.
5. Examples of solving typical problems17
Compiled by: Davis D. Research in advertising activities: theory and practice / Transl. from English – M.: Williams, 2003. – pp. 243–248.
Example 1. Determine the final sample size if three alternative questions requiring an “agree–disagree” response were developed for the research. The first question is expected to receive an affirmative answer from 10% of the sample, the second – 20%, and the third – 85%. In addition, it is necessary to ensure a narrow confidence interval not exceeding ±3% for each of the three questions separately.
Solution. To solve this problem it is necessary to use the data of the appendix. 4. From the table presented in appendix. 4, it is clear that with a confidence interval with a value not exceeding ±3% with the expected proportion of affirmative answers:
– 10% – sample size should be 400;
– 20% – sample size should be 700;
– 85% – sample size should be about 600.
Therefore, the final sample size at these values should be 700 people (the largest of the three required sample sizes).
Answer: 700 people.
Example 2. Let’s assume that you need to get an answer from a group of respondents to the question: “Are you familiar with the advertising of cakes produced by Zhuravli Factory-Kitchen OJSC?”, expecting to receive an affirmative answer from 35% of respondents. In this case, you need to be 99% sure that the actual proportion of positive answers will be within ±2%. What would be the sample size if the confidence level is 95% and the confidence interval is ±4%?
Solution. The required sample size at a given confidence level is determined by the formula:

p – expected share;
e – desired confidence interval.
Z-scores for various confidence levels are given in Table. 19.
Table 19
Z-score value
Substituting the values, we get:
The sample size is large because the confidence level and confidence interval set a high level of precision. The sample size will be much smaller if the confidence interval increases to ±4% and the confidence level decreases to 95%:

Answer: 3756 people; 546 people
Example 3. Let the population size be 375,557 people. It is required to determine the sample size, if the confidence level is 95%, the confidence interval is ±0.05.
Solution.
We present the solution to this problem in the form of a table. 20.
Table 20
Determining sample size

Answer: 350 people
Example 4. Imagine the following situation. You turned to a group of respondents with a request: “Please give an assessment of the credibility of the advertisement of the computer salon of OJSC “Supercomp” on a scale from one to five.” What would be the sample size if you wanted to be 95% confident that the true population mean rating would be within ±0.4 of the sample mean?
Solution.
At the first stage, we will evaluate the standard deviation. It can be obtained by summing the extreme values of the scale and dividing the sum by four:
s = (5 + 1): 4 = 1.5
The required sample size for a given desired confidence level can be calculated using the formula:

where z is the z-score corresponding to the required confidence level;
e – desired confidence interval;
s 2 – standard deviation.
Answer: 54 people
6
Task 1. Fill in the blanks in the table. 21, indicating the advantages and disadvantages of sampling methods.
Table 21
Comparative analysis of sampling methods

Problem 2. For each of the following situations, determine the target population:
a) OJSC “Dairy Plant” wants to receive information about the reasons for the low activity of buyers of dairy products in the plant’s advertising campaigns;
b) a wholesaler engaged in the sale of household electrical appliances in the city of N wants to evaluate the consumer reaction to a campaign to stimulate everyday life;
c) The city's central department store wishes to receive information about the effectiveness of advertisements placed in the local newspaper;
d) a national manufacturer of cosmetics wants to ensure that wholesalers have sufficient inventory to avoid stockouts at retailers;
e) the university cafe intends to test a new soft drink produced by its employees.
Task 3. The administration of a popular tourist resort decided to determine the attitude of tourists who visit the resort to certain types of active recreation. A notice was planned to be delivered to each room of the resort's two largest hotels, informing guests of the purpose, time and location of the study. Those wishing to participate in the survey had to proceed to the hotel lobby, where it was planned to install special tables:
a) what method is used to select sample elements?
Task 4. The management of the Bogatyr company, a manufacturer of plus-size clothing, decided to change the company’s marketing strategy. This was preceded by a series of target group surveys. The groups surveyed consisted of 10–12 large men and women with different demographic characteristics, who were selected based on physical characteristics right on the street:
a) by what method are sample elements selected?
b) give a critical assessment of the selection method used.
Task 5. The percentage of families with a DVD player and the average time of use during the week are determined. The required level of accuracy is 95%, the maximum error is ±3% for the number of owners and ±1 hour for the time of use. A previous study found that 20% of households owned DVD players; the average time of use is 15 hours per week with a standard deviation of 5 hours:
a) what should be the sample size to determine the number of households with DVD players?
b) what should be the sample size to determine the average time spent using DVD players?
c) what should be the sample size to determine both of the above parameters? Why?
Task 6. The general population is described by the following characteristics (Table 22). Based on these three benchmarks, determine the performance of a sample of 200 items.
Table 22
Characteristics of the population

Problem 7. OJSC "Beer" plans to change the label on its main products:
a) identify the population and sampling frame that can be used in this case;
b) describe how to obtain a simple random sample using your established sampling frame;
c) Is it possible to conduct stratified sampling? If yes, then how?
d) is it possible to use cluster sampling? If yes, then how?
e) which sampling method do you recommend? Why?
Task 8. Fill out the table. 23, specifying the criteria that determine the appropriateness of using a sample or a census.
Table 23
Criteria for determining whether a sample or census is appropriate

Task 9. What effect would a 25% reduction in the absolute accuracy of the general mean have on the sample size? Reducing the confidence level from 95 to 90%?
Problem 10. Suppose you need to get an answer from a group of respondents to the question: “Are you familiar with the advertising of drinking yoghurts produced by OJSC Dairy Plant?”, expecting to receive an affirmative answer from 45% of respondents. In this case, you need to be 99% sure that the actual proportion of positive answers will be within ±3%. What would be the sample size at the 95% confidence level and ±4% confidence interval?
Problem 11. Imagine the following situation. You turned to a group of respondents with a request: “Please give an assessment of the credibility of advertising cabinet furniture produced by the Katyusha furniture concern on a scale of one to five.” What would be the sample size if you wanted to be 95% confident that the true value of the population mean rating would be within ±0.5 of the sample mean?
Problem 12. Determine the final sample size if three alternative questions requiring an “agree–disagree” response were developed for the research. The first question is expected to receive an affirmative answer from 20% of the sample, the second – 35%, and the third – 65%. In addition, it is necessary to provide a narrow confidence interval, which is within ±4% for each of the three questions separately.
7. Discussion
Read and discuss the following statements:
1. The greater the differences (heterogeneity) within the population, the greater the possible sampling error.
2. The sample size depends on the level of homogeneity or heterogeneity of the objects being studied. The more homogeneous they are, the smaller the numbers can provide statistically reliable conclusions.
3. Determination of the sample size depends on the level of the confidence interval of the permissible statistical error. This refers to the so-called random errors associated with the nature of any statistical errors.
4. The most reliable result, under certain conditions, can be obtained by a continuous study or census.
5. Each sample has a certain level of representativeness and an associated error rate.
6. There is a certain sample size limit, exceeding which does not significantly increase the accuracy of the results.
7. The most “soft” requirements are imposed on the sample of a study pursuing intelligence purposes. The main principle here is to identify “polar” groups according to criteria essential for analysis. The size of such samples is not strictly determined. The collection of information continues until the researcher accumulates a variety of information that is not representative, but quite sufficient to formulate hypotheses.
8. Stratified sampling is more accurate than simple random sampling.
9. Most cases of unintentional data falsification occur at the sampling stage. There are few specialists in competent sampling in Russia, so even in some well-known companies the sampling is not compiled professionally enough.
10. All research methods have potential errors. And no one can be immune from them. The solution is to engage in marketing research systematically and at a professional level, then experience and knowledge will allow you to successfully overcome most bottlenecks 18
Tokarev B. E. Marketing research. – M.: Economist, 2007. – P. 582–583.
8. Control test
1. What do you see as the advantages or disadvantages of selective observation in marketing? _______________________________.
2. Does sample observation provide the study of all or part of the units in the population?
a) provides;
b) provides partially;
c) I don’t know.
3. Does sampling allow you to save money on conducting a survey?
a) allows;
b) does not allow.
4. Does a partial survey provide complete information?
a) has;
b) does not have.
5. Does sample observation allow one to reliably judge the entire population by its part?
c) I don’t know.
Topic 5. DATA COLLECTION FORM
1. Problems to solve independently
Problem 1. Identify the type of scale used in each of the following questions. Justify your answer:
a) what time of year do you usually plan your vacation?
b) your family's total income? _________________.
c) What are your three favorite brands of shampoo? Rate them from 1 to 3 according to your preferences, assigning 1 as your most preferred:
– Pantene Pro-V;
d) how much time do you spend on the road from home to university every day:
– less than 5 minutes;
– 5–15 min;
– 16–20 minutes;
– 21–30 min;
– 30 minutes or more;
e) how satisfied are you with the magazine “Marketing and Advertising”:
- very satisfied;
- satisfied;
– both satisfied and dissatisfied;
– dissatisfied;
- very displeased;
f) how many cigarettes do you smoke per day on average?
– more than one pack;
– from half a pack to one whole;
– less than half a pack;
g) your level of education:
– unfinished secondary;
– completed secondary;
– unfinished higher education;
- completed higher education.
Problem 2. Below is an analysis for each of the preceding questions. Is the analysis used appropriate for the type of measurement scale in each case?
A. About 50% of the sample goes on vacation in the fall, 25% in the spring, and the remaining 25% in the winter. We can conclude that in the fall there are twice as many vacationers as in the spring and winter seasons.
B. The average total income of one family member is 15 thousand rubles. Respondents with a total income of less than 15 thousand rubles. 67%, with an income of more than 15 thousand rubles. – 33%.
Q. Pantene Pro-V is the most preferred brand. Its average preference value is 3.52. D. The median value of all answer options about the time spent traveling from home to the university is 8.5 minutes. Three times more respondents spend less than 5 minutes on the road compared to the number of those who spend 16–20 minutes.
D. The average satisfaction score is 4.5, which appears to indicate the high level of satisfaction received by the readers of Marketing and Advertising magazine.
E. 10% of respondents smoke less than half a pack of cigarettes per day, while 90% of respondents smoke more than one pack per day.
G. The answers show that 40% of respondents have incomplete secondary education, 25% graduated from high school, 20% have incomplete higher education and 15% graduated from higher educational institutions.
Task 3. The MIR advertising agency intends to study the level of awareness and consumer perception of an advertising campaign developed for OJSC Dairy Plant. It was decided to conduct quantitative research. The target audience of the advertisement and, accordingly, the sample population of the study were women aged 20 years and older, living in the city of N and currently having children under the age of 10 years. The advertising campaign was carried out to inform consumers about new products intended for baby food. Your client, OJSC Dairy Plant, wants to know whether the purpose of the research should be hidden from the respondent. What questions will you ask the Marketing Director of Dairy Plant OJSC and what information do you need in order to make a decision? What factors will influence your decision not to disclose the purpose of the study when developing a questionnaire for OJSC Dairy Plant? What are the advantages and disadvantages of concealing the purpose of the research when conducting this research project?
a) which of the following newspapers do you read regularly:
- “Bryansk worker”;
- "TVNZ";
– “Economic Newspaper”;
b) how often do you purchase products from OJSC “Dairy Plant”:
c) you agree that the government should impose import restrictions on:
- I certainly agree;
- agree;
– neither against nor for;
– I don’t agree;
- definitely, - disagree;
d) how often do you purchase Cif detergent:
- once a week;
- once in two weeks;
– once every three weeks;
- once a month;
d) what social group do you belong to?
- worker;
– employee;
– manager;
– other;
f) where do you usually buy office supplies?
g) when you watch TV, do you watch advertisements?
i) which brand of tea are you most familiar with:
j) what do you think, should the Russian government, in the context of the global financial crisis, continue the current policy of cutting taxes and cutting government spending:
k) how often during the week do you exercise:
- every day;
– 5–6 times a week;
– 2–4 times a week;
- once a week;
a) which of the following reasons is most important for you when choosing a TV:
– service in the store;
- trademark;
– level of defects;
- guarantees;
b) indicate your level of education:
– less than high school;
– unfinished secondary;
- high school;
– secondary technical;
– unfinished higher education;
– completed higher education;
– higher professional;
c) what is your average monthly income:
– less than RUB 4,500;
– RUB 4,501–10,000;
– 10,001–20,000 rubles;
– 20,001–50,000 rubles;
– more than 50,001 rubles;
d) your average monthly income?
- high;
- average;
– minimal.
Task 6. Select at least five brands from the same product line from well-known manufacturers, for example, shampoo, cars, chocolate, etc. List 5–10 parameters (properties, qualities) by which these products can be assessed, then:
Table 24
Constant Sum Scale Assessment Results

c) modify the table. 25, assigning a rank to each parameter in accordance with its significance, ranging from 0 (least preferable) to 1 (most preferable), summarize the results in table. 25, draw a conclusion, compare with the results of previous tasks;
Table 25
Evaluation results on a constant sum scale taking into account rank

d) rate these products on a modified Likert scale using seven rating options: 7 – wonderful; 6 – very good; 5 – good; 4 – mediocre; 3 – bad; 2 – very bad; 1 – worthless (Table 26);
Table 26
Modified Likert scale assessment results

Table 27
Comparison of products by parameter a (b, c, …)

Determine the number of cases of preference for each product over all other products:

where f Si is the total number of preferences for product S i relative to other products (determined by counting the number of “units” in the corresponding line in all tables);
n – number of goods;
m – number of parameters by which the assessment is carried out;
f ksij – frequency (assessment) of choosing product S i in preference to product S j.
Calculate the generalized weight for each product:
where W is the generalized weight of product S in fractions of a unit ();
J – total number of ratings received:

Multiply the generalized weights by 100 and compare them with the results of previous assignments.
Task 7. Select five brands from different manufacturers of any product group (for example, dairy products, chocolate, coffee, etc.). Write questions about this range of brands under study using nominal, ordinal, interval and ratio scales. Answer the questions provided. Which ones are more difficult to answer and why?
Problem 8. Students need to break into groups of three to four people. Using the method of paired comparisons, each member of the group needs to evaluate five to six television commercials according to criteria such as the originality of the author's idea, memorability, and motivating the consumer to purchase. Then it is necessary to assess the degree of consistency of opinions, calculate the integral rating of the videos and determine the best one.
Task 9. Using the paired comparison method on behalf of three experts, evaluate five brands of tea based on criteria such as aroma, richness, taste, and price. In accordance with their opinion, calculate the integral rating of the tea and determine the best one.
Problem 10. Calculate the subjective integral assessment of 10 websites of the largest Russian marketing research companies according to the following criteria: completeness of information about the services provided, completeness of information about the company, design, ease of navigation. Determine the significance of these characteristics.
Problem 11. Develop a semantic differential scale to measure the image of two universities in the city. Present your scale to a pilot sample of 20 students. Based on your research, answer the question: Which university has a more favorable image? What other methods can be used to evaluate the image of universities?
Problem 12. Develop a Likert scale to measure the image of two banks in your city. Present this scale to a pilot sample of 20 students. Based on your research, answer the question: which bank has a more favorable image?
Problem 13. Develop a Stapel scale to measure the image of two city retail chains. Present this scale to a pilot sample of 20 students. Based on your research, answer the question: Which chain has a more favorable image?
Problem 14. Develop a questionnaire to determine how students choose their vacation destination. Pre-test the questionnaire by presenting it to 10 students through personal interviews. How would you modify the questionnaire after the pretest?
Problem 15. In December 2008, in one of the clinics in city A, a unique electronic registrar appeared, which allows patients to make an appointment at a convenient time, bypassing the usual system: getting up at six in the morning - queue - coupon. Externally, the electronic register, or information kiosk, is similar to a regular ATM. It is located on the first floor of the clinic, right at the entrance. Anyone can enter their health insurance number and see the opening hours of a medical institution and/or a specific specialist on the screen, as well as make an appointment. Women also have access to information about reception hours at the antenatal clinic located at the other end of the city, as well as about the work schedules of pediatricians at the children's clinic. A professional monitors what is happening on the screen at the reception. Since the kiosk operates online, the requested information in the register is recorded, analyzed and systematized. The patient’s outpatient card is sent to the office of the doctor he needs, and information about this is added to the database 19
Privalenko O. I’ll make an appointment with the doctor myself // Arguments and facts. – 2008. – No. 51(376).
What data collection method is used in this situation? How can the information obtained be used? How can it improve the efficiency of the clinic?
Problem 16. The company is a specialized retail store “Coffee Paradise”. The purpose of the marketing research is to understand how coffee consumption will change in the next two years. The company plans to use the following methods:
– focus groups with consumers – real and potential;
– in-depth interviews and a mass survey of coffee lovers and non-coffee drinkers, assessment of factors influencing their choice.
The company wants to obtain information about market capacity and its dynamics; motivation of coffee consumers; description of situations of purchase and consumption of coffee, assessment of demand by segment, its price elasticity. It is planned that the result of the study will be models of consumer behavior; forecast for 2–4 years; clarification of brand positioning, justification of pricing strategy; formation of the concept of the brand promotion program. You work as a marketer for a company, and you are tasked with developing forms to collect information.
Problem 17. Using the observation form (Appendix 6), conduct a study to find out the number, gender and age of customers visiting the store. What conclusions can be drawn from the observation results? What changes can be made to the observation form?
Problem 18. The management of the meat processing plant was faced with a drop in sales and decided to study its reasons as soon as possible. It was decided to conduct a personal interview, the questionnaire for which is presented in the appendix. 7.
Problem 19. To the direct question “Do you have a DVD player?” 72% of positive responses were given. And to the indirect question “Are you going to buy a DVD player in the near future?” 57% of respondents said that they already have a player. However, there were much fewer positive answers than with the first version of the question. Explain the disadvantages of direct and advantages of indirect surveys.
Problem 20. Let's assume that you work for a marketing agency that has given you the task of developing a form for monitoring the service personnel of one of the plastic window companies. In other words, you and your colleagues need to visit the company under the guise of an ordinary client, ask typical “buying” questions based on the “legend” agreed upon with the customer, and maybe even buy something. Based on the results of the visit outside the company, you must fill out a detailed questionnaire. The questionnaire may contain from 15 to 35 parameters on which company personnel must be assessed. Compose a questionnaire using the following parameters: compliance with corporate appearance standards (dress code); knowledge of the products sold, their consumer properties and features; product presentation skills; customer service skills (or active sales and business communication skills); implementation of current marketing campaigns (product of the day, sale of discount cards, promotion of new brands, etc.). If necessary, add new parameters to the questionnaire. Answer the questions as well.
Each researcher can create his own scale, but it is hardly worth doing this. It is better to choose a scale from among standard scales that are original in the sense that they have their own name, are widely used, and are included in the most commonly used system of scales. They are also called original. Next, four discrete rating scales are considered: Likert, semantic differential, graphic rating and Stepel, as well as a constant sum scale and a ranking scale.
Likert scale based on choosing the degree of agreement or disagreement with some specific statement. In fact, one pole of this essentially bipolar ordinal scale is formulated, which is much simpler than naming both poles. The formulation of the statement may correspond to the ideal level of some parameter of the object. When characterizing a higher educational institution, one can consider its following properties: qualified teaching staff, equipped classrooms with technical means, modernity and regularity of updating training courses, availability e-leming in educational technologies, level of culture, image and reputation, student population and many others. The wording of the statements could be as follows: the teaching staff of this university is very qualified; the university has a very high level of use of modern teaching aids; this university educates students seeking knowledge; graduates of this university are highly valued in the labor market.
When using a Likert scale, five gradations are usually considered. An example of using a Likert scale in a questionnaire is shown in Fig. 8.1. In other words, the questions are formulated in a Likert scale format. The respondent is asked to tick one of five boxes.
Rice. 8.1.
In this case, the quantitative assessment itself is not required from the respondent, although more often points can be immediately given next to the names of the gradations. As can be seen from Fig. 8.1, the degree of agreement or disagreement with each statement made can have the following gradations: strongly disagree (1 point), disagree (2 points), neutral (3 points), agree (4 points), definitely agree (5 points). Here in brackets is the most commonly used option for digitizing the scale. It is also possible that a higher score (5 points) corresponds to the “strongly disagree” gradation.
Semantic differential and graphic rating scale
Semantic differential scale presupposes the presence of two polar semantic meanings (antonyms) or antonymic positions, between which there is an odd number of gradations. In this sense, the scale is bipolar. As a rule, seven gradations are considered. The middle position (middle gradation) is considered neutral. Digitization of scale gradations can be unipolar, for example in the form "1, 2, 3, 4, 5, 6, 7", or bipolar, for example in the form "-3, -2, -1, 0, 1, 2, 3".
Usually the poles of the scales are specified verbally (verbal). Examples of scales with two poles are as follows: “calming – invigorating” or “compact – voluminous”. Along with verbal semantic differentials, non-verbal semantic differentials have been developed that use graphic images as poles.
Examples of verbal semantic differentials are given in Fig. 8.2.

Rice. 8.2.
The semantic differential resembles the Likert scale, but has the following differences: 1) both polar statements are formulated instead of one; 2) instead of the names of intermediate gradations, a sequential graphical arrangement of an odd number of gradations located between the extreme values “good - bad” is given.
Semantic differential method (from Greek. sematicos – denoting and lat. differentia difference) was proposed by the American psychologist Charles Osgood in 1952 and is used in studies related to human perception and behavior, with the analysis of social attitudes and personal meanings, in psychology and sociology, in the theory of mass communications and advertising, and in marketing.
Can be considered as an analogue of the semantic differential scale. The rating scale is implemented in such a way that each property is associated with a line, the ends of which correspond to polar statements, for example: “not important” and “very important”, “good” and “bad” (Fig. 8.3).
Rice. 8.3.
The fundamental difference between the compared scales is that the semantic differential is a discrete scale, and, as a rule, it has seven gradations, and the graphic rating scale is continuous.
- Thus, when characterizing the exterior of certain car brands, they sometimes say that it is characterized by brutality. There are also simpler examples - ergonomics and controllability, when it is difficult to meaningfully name the second pole.
E.P. Golubkov Academician of the International Academy of Informatization, Doctor of Economics, Professor of the Academy of Economy under the Government of the Russian Federation
1. Measurement scales
To collect data, questionnaires are developed. Information to fill them out is collected by taking measurements. By measurement we mean the determination of a quantitative measure or density of a certain characteristic (property) of interest to the researcher.
Measurement is a procedure for comparing objects according to certain indicators or characteristics (attributes).
Measurements can be qualitative or quantitative in nature and can be objective or subjective. Objective qualitative and quantitative measurements are made by measuring instruments, the operation of which is based on the use of physical laws. The theory of objective measurements is quite well developed.
Subjective measurements are made by a person who, as it were, acts as a measuring device. Naturally, with subjective measurement, its results are influenced by the psychology of a person’s thinking. A complete theory of subjective measurements has not yet been constructed. However, we can talk about creating a general formal scheme for both objective and subjective measurements. Based on logic and the theory of relations, a theory of measurements has been built, which allows us to consider both objective and subjective measurements from a unified position.
Any measurement includes: objects, indicators and a comparison procedure.
The indicators (characteristics) of certain objects (consumers, product brands, stores, advertising, etc.) are measured. Spatial, temporal, physical, physiological, sociological, psychological and other properties and characteristics of objects are used as indicators for comparing objects. The comparison procedure involves defining the relationships between objects and how they are compared.
The introduction of specific comparison indicators allows you to establish relationships between objects, for example, “more”, “less”, “equal”, “worse”, “preferable”, etc. There are various ways to compare objects with each other, for example, sequentially with one object taken as a standard, or with each other in a random or ordered sequence.
Once a characteristic has been determined for a selected object, the object is said to have been measured against that characteristic. Objective properties (age, income, amount of beer drunk, etc.) are easier to measure than subjective properties (feelings, tastes, habits, relationships, etc.). In the latter case, the respondent must translate his ratings into a density scale (some numerical system) that the researcher must develop.
Measurements can be taken using various scales. There are four characteristics of scales: description, order, distance and the presence of a starting point.
The description assumes the use of a single descriptor or identifier for each gradation in the scale. For example, “yes” or “no”; “agree” or “disagree”; age of respondents. All scales have descriptors that define what is being measured.
The order characterizes the relative size of the descriptors (“greater than”, “less than”, “equal”). Not all scales have order characteristics. For example, one cannot say more or less “buyer” compared to “non-buyer.”
A scale characteristic such as distance is used when the absolute difference between the descriptors is known, which can be expressed in quantitative units. A respondent who bought three packs of cigarettes bought two more packs compared to a respondent who bought only one pack. It should be noted that when “distance” exists, order also exists. The respondent who bought three packs of cigarettes bought them “more than” the respondent who bought only one pack. The distance in this case is two.
A scale is considered to have a starting point if it has a single origin or zero point. For example, the age scale has a true zero point. However, not all scales have a zero point for the properties being measured. Often they only have an arbitrary neutral point. For example, answering a question about the preference of a certain brand of car, the respondent answered that he had no opinion. The gradation “I have no opinion” does not characterize the true zero level of his opinion.
Each subsequent characteristic of the scale is built on the previous characteristic. Thus, “description” is the most basic characteristic that is inherent in any scale. If a scale has “distance”, it also has “order” and “description”.
There are four levels of measurement that determine the type of measurement scale: names, order, interval and ratios. Their relative characteristics are given in table. 1.
Table 1
Characteristics of various types of scales
The naming scale has only the characteristic of description; it assigns only its name to the described object; no quantitative characteristics are used. Objects of measurement fall into many mutually exclusive and exhaustive categories. The naming scale establishes relations of equality between objects that are combined into one category. Each category is given a name, the numerical designation of which is an element of the scale. Obviously, measurement at this level is always possible. “Yes”, “No” and “Agree”, “Disagree” are examples of gradations of such scales. If respondents were classified according to the type of their activity (name scale), then it does not provide type information; “more than”, “less than”. In table 2 provides examples of questions formulated both in the name scale and in other scales.
table 2
Examples of questions formulated in different measurement scales
A. Scale of names
1. Please indicate your gender: male, female
2. Select the brands of electronic products that you usually buy:
-Sony
-Panasonic
-Phillips
-Orion
-etc.
3. Do you agree or disagree with the statement that the image of the Sony company is based on the production of high quality products? I agree I disagree
B. Order scale
1. Please rank electronic product manufacturers according to your preference system. Put “1” to the company that ranks first in your preference system; “2” – second, etc.:
-Sony
-Panasonic
-Phillips
-Orion
-etc.
2. For each pair of grocery stores, circle the one you prefer:
Kroger and First National
First National and A&P
A&P and Kroger
3. What can you say about the prices at Vel-Mart:
They're higher than Sears.
Same as at Sears
Lower than Sears.
B. Interval scale
1. Please rate each brand of product in terms of its quality:
2. Please indicate your level of agreement with the following statements by circling one of the numbers:
d. Relationship scale
1. Please indicate your age_________ years
2. Indicate approximately how many times over the last month you made purchases in a store on duty in the time interval from 20 to 23 hours
0 1 2 3 4 5 another number of times _______
3. How likely is it that you will seek the help of a lawyer when making a will?
______________ percent
The order scale allows you to rank respondents or their answers. It has the properties of a naming scale combined with an order relation. In other words, if each pair of categories of the naming scale is ordered relative to each other, then an ordinal scale will be obtained. In order for scale ratings to differ from numbers in the ordinary sense, they are called ranks at the ordinal level. For example, the frequency of purchasing a certain product (once a week, once a month or more often). However, such a scale only indicates the relative difference between the objects being measured.
Often the supposed clear distinction between assessments is not observed and respondents cannot unambiguously choose one answer or another, i.e. some adjacent gradations of answers overlap each other. Such a scale is called semi-ordered; it lies between the scales of names and order.
The interval scale also has the characteristic of the distance between individual gradations of the scale, measured using a specific unit of measurement, that is, quantitative information is used. On this scale, the differences between individual gradations of the scale are no longer meaningless. In this case, you can decide whether they are equal or not, and if they are not equal, then which of the two is greater. Scale values of signs can be added. It is usually assumed that the scale is uniform (although this assumption requires justification). For example, if store clerks are rated on a scale of extremely friendly, very friendly, somewhat friendly, somewhat unfriendly, very, unfriendly, extremely unfriendly, then it is usually assumed that the distances between the individual gradations are the same (each value from the other differs by one - see Table 2).
The ratio scale is the only scale that has a zero point, so quantitative comparisons can be made between the results obtained. This addition allows us to talk about the ratio (proportion) a: b for scale values a and b. For example, a respondent may be 2.5 times older, spend three times more money, and fly twice as often as another respondent (Table 2).
The selected measurement scale determines the nature of the information that the researcher will have when conducting a study of an object. But rather, it should be said that the choice of scale for measurements is determined by the nature of the relationship between objects, the availability of information and the goals of the study. If, say, we want to rank brands of products, we usually don't need to determine how much better one brand is than another. Therefore, there is no need to use quantitative scales (intervals or ratios) for such measurements.
In addition, the type of scale determines what type of statistical analysis can or cannot be used. When using a naming scale, it is possible to find distribution frequencies, the average trend in modal frequency, calculate coefficients of interdependence between two or more series of properties, and use nonparametric criteria for testing hypotheses.
Among statistical indicators at the ordinal level, indicators of central tendency are used - median, quartiles, etc. To identify the interdependence of two characteristics, Spearman and Kendal rank correlation coefficients are used.
Quite a variety of actions can be performed on numbers belonging to the interval scale. The scale can be compressed or expanded any number of times. For example, if the scale has divisions from 0 to 100, then by dividing all the numbers by 100, we get a scale with values from 0 to 1. You can shift the entire scale so that it consists of numbers from -50 to +50.
In addition to the algebraic operations discussed above, interval scales allow all statistical operations inherent in the ordinal level; It is also possible to calculate the arithmetic mean, variance, etc. Instead of rank correlation coefficients, the Pearson pairwise correlation coefficient is calculated. A multiple correlation coefficient may also be calculated.
All of the above calculation operations are also applicable to the ratio scale.
It must be borne in mind that the results obtained can always be translated into a simpler scale, but never vice versa. For example, the gradations “strongly disagree” and “somewhat disagree” (interval scale) can easily be transferred to the “disagree” category of the naming scale.
Using measurement scales
In the simplest case, an assessment of a measured characteristic by a certain individual is made by selecting, as a rule, one answer from a series of proposed ones or by selecting one numerical score from a certain set of numbers.
To assess the quality being measured, graphic scales are sometimes used, divided into equal parts and provided with verbal or numerical symbols. The respondent is asked to make a mark on the scale in accordance with his assessment of this quality.
As stated above, ranking objects is another commonly used measurement technique. When ranking, an assessment is made of the measurable quality of a set of objects by ordering them according to the degree of expression of this characteristic. The first place, as a rule, corresponds to the highest level. Each object is assigned a score equal to its place in this ranked series.
The advantage of ranking as a method of subjective measurement is the simplicity of the procedures, which does not require any labor-intensive training of experts. However, it is almost impossible to organize a large number of objects. As experience shows, when the number of objects is more than 15–20, experts find it difficult to construct rankings. This is explained by the fact that in the ranking process the expert must establish the relationship between all objects, considering them as a single set. As the number of objects increases, the number of connections between them increases in proportion to the square of the number of objects. Storing in memory and analyzing a large set of relationships between objects is limited by the psychological capabilities of a person. Therefore, when ranking a large number of objects, experts can make significant errors. In this case, the paired comparison method can be used.
Pairwise comparison is the procedure of establishing a preference for objects when comparing all possible pairs and further ordering the objects based on the results of the comparison. Unlike ranking, in which the ordering of all objects is carried out, pairwise comparison of objects is a simpler task. Paired comparison, like ranking, is a measurement on an ordinal scale.
However, this approach is more complex and is more likely to be used when surveying experts rather than mass respondents.
Let us assume that the attitude towards such product values as “benefit”, “design”, “quality”, “warranty period”, “after-sales service”, “price”, etc. is being clarified. We assume that simple ranking (determining the weights of features ) it is difficult or quite important to accurately determine the scale weights of the characteristics under study, so their direct expert determination cannot be carried out. For simplicity, let us denote these values by the symbols A1, A2, A3,..., Ak.
Respondents (experts) compare these characteristics in pairs in order to determine the most important (significant) of them in each pair.
From the symbols we form all kinds of pairs: (A1A2), (A1A3), etc. The total number of such paired combinations will be x (k – 1)/2, where k is the number of evaluated features. Then the objects are ranked based on the results of their pairwise comparison, .
The method of paired comparisons can also be used to determine the relative weights of goals, criteria, factors, etc., carried out when conducting various marketing research.
In many cases, when compiling questionnaires, it is not advisable to develop measurement scales from scratch. It is better to use the standard types of scales used in the market research industry. These scales include: the modified Likert scale, the life style scale and the semantic differential scale.
Based on a modified Likert scale (interval scale), adapted to the purposes of the marketing research being conducted, the degree of agreement or disagreement of respondents with certain statements is studied. This scale is symmetrical in nature and measures the intensity of the respondents’ feelings.
In table Figure 3 shows a questionnaire based on a Likert scale. This questionnaire can be used to conduct telephone surveys of consumers. The interviewer reads out the questions and asks the respondents to indicate the degree of their agreement with each statement.
Table 3
Questionnaire to identify consumer opinions regarding a product of a certain brand
There are various options for modifying the Likert scale, for example, introducing a different number of gradations (7 – 9).
The scale for studying life style is a special area of application of the modified Likert scale and is designed to study the system of values, personal qualities, interests, opinions regarding work, leisure, and purchases of various people. Such information allows you to make effective marketing decisions. An example of a questionnaire for studying life style is given in Table. 4.
Table 4
Life style survey
Please circle the number that best represents your level of agreement or disagreement with each statement.
| Statement | Strongly agree | I agree to some extent | I'm neutral | To some extent I disagree | Strongly disagree |
| 1. I buy a lot of special items | 1 | 2 | 3 | 4 | 5 |
| 2. I usually have one or more of the latest fashions. | 1 | 2 | 3 | 4 | 5 |
| 3. The most important thing for me is my children. | 1 | 2 | 3 | 4 | 5 |
| 4. I usually keep my house in great order. | 1 | 2 | 3 | 4 | 5 |
| 5. I prefer to spend the evening at home than go to a party | 1 | 2 | 3 | 4 | 5 |
| 6. I like to watch or listen to broadcasts of football matches. | 1 | 2 | 3 | 4 | 5 |
| 7. I often influence my friends’ requests. | 1 | 2 | 3 | 4 | 5 |
| 8. Next year I will have more money for shopping. | 1 | 2 | 3 | 4 | 5 |
The semantic differential scale contains a series of bipolar definitions that characterize various properties of the object being studied. Since many marketing stimuli are based on mental associations and relationships that are not explicitly expressed, this type of scale is often used to determine the image of a brand, store, etc. The results of studying consumer opinions regarding two restaurants (#1 and #2) based on a semantic differential scale are given in Table. 5.
Table 5
Comparative assessment of two restaurants
Designations: solid line – ratings of restaurant #1, dotted line – restaurant #2.
In table 5 specifically, all positive or negative ratings are not located only on one side, but are randomly mixed. This is done in order to avoid the “halo effect”. It lies in the fact that if the first object being assessed has higher first ratings (the left side of the questionnaire) compared to the second object, then the respondent will tend to continue to give ratings to the left.
One of the advantages of this method is that if individual gradations in the scale are assigned numbers: 1, 2, 3, etc., and the data of different respondents is entered into the computer, then the final results can be obtained in graphical form (Table 5 ).
When using the above scales, the question arises about the advisability of using a neutral point. It all depends on whether respondents have a neutral opinion or not. It is not possible to give an unambiguous recommendation on this issue.
The same can be said regarding whether to build a symmetrical or asymmetrical scale.
There are a great variety of scale options built on the basis of the stated principles. The final choice is usually made based on testing the level of reliability and accuracy of measurements made using various scale options.
Reliability and validity of marketing information measurement
The methods for constructing scales described above do not provide a complete picture of the properties of the resulting estimates. Additional procedures are needed to identify the inherent errors in these estimates. Let's call this the measurement reliability problem. This problem is addressed by identifying measurement validity, robustness, and validity.
When studying accuracy, the general acceptability of a given method of measurement (scale or system of scales) is established. The concept of correctness is directly related to the possibility of taking into account various types of systematic errors as a result of measurement. Systematic errors have a certain stable nature of occurrence: either they are constant or vary according to a certain law.
Stability characterizes the degree of agreement between measurement results during repeated applications of the measurement procedure and is described by the magnitude of the random error. It is determined by the consistency of the respondent’s approach to answering the same or similar questions.
For example, you are one of the respondents answering the questions in the questionnaire in Table. 5 regarding the activities of a restaurant. Because of the slow service at this restaurant, you were late for a business meeting, so you gave the lowest rating for this indicator. A week later they called you and asked you to confirm that you actually took part in the survey. You were then asked to answer a series of follow-up questions over the phone, including a question about speed of service on a scale of 1 to 7, with 7 being the fastest service. You gave a 2, demonstrating a high level of identity of the ratings and, therefore, the stability of your ratings.
The most difficult issue of measurement reliability is its validity. Validity is associated with proof that a very specific specified property of an object was measured, and not some other, more or less similar to it.
When establishing reliability, it should be borne in mind that three components are involved in the measurement process: the object of measurement, the measuring means with the help of which the properties of the object are mapped to the numerical system, and the subject (interviewer) making the measurement. The prerequisites for reliable measurement lie in each individual component.
First of all, when a person acts as an object of measurement, he may have a significant degree of uncertainty in relation to the property being measured. Thus, often the respondent does not have a clear hierarchy of life values, and therefore, it is impossible to obtain absolutely accurate data characterizing the importance of certain phenomena for him. He may be poorly motivated, as a result of which he inattentively answers questions. However, only as a last resort should one look for the reason for the unreliability of estimates in the respondent himself.
On the other hand, it may be that the method for obtaining the assessment is not able to provide the most accurate values for the property being measured. For example, a respondent has a detailed hierarchy of values, and to obtain information a scale with variations of answers only “very important” and “not at all important” is used. As a rule, all values from the given set are marked with the answers “very important,” although in reality the respondent has a larger number of levels of importance.
Finally, in the presence of high accuracy of the first two components of the measurement, the subject making the measurement makes gross errors; the instructions for the questionnaire are unclear; The interviewer formulates the same question differently each time, using different terminology.
For example, during the interview, during which the value system of the respondent should be revealed, the interviewer was unable to convey to the respondent the essence of the survey, was unable to achieve a friendly attitude towards the research, etc.
Each component of the measurement process can be a source of error related to either robustness, accuracy, or validity. However, as a rule, the researcher is not able to separate these errors by their sources and therefore studies errors in the stability, correctness and validity of the entire measurement complex in its entirety. At the same time, correctness (as the absence of systematic errors) and stability of information are elementary prerequisites for reliability. The presence of a significant error in this regard already negates the validity check of the measurement data.
Unlike correctness and stability, which can be measured quite strictly and expressed in the form of a numerical indicator, validity criteria are determined either on the basis of logical reasoning or on the basis of indirect indicators. Typically, a comparison of data from one technique with data from other techniques or studies is used.
Before you begin to study reliability components such as stability and validity, you need to make sure that the chosen measurement tool is correct.
It is possible that subsequent stages will turn out to be unnecessary if at the very beginning it turns out that the instrument is completely incapable of differentiating the population being studied at the required level, in other words, if it turns out that some part of the scale or this or that gradation of the scale or question is not systematically used. And finally, it is possible that the original feature does not have differentiating ability in relation to the object of measurement. First of all, it is necessary to eliminate or reduce such shortcomings of the scale and only then use it in the study.
The disadvantages of the scale used include, first of all, the lack of scattering of responses across the scale values. If the answers fall into one point, this indicates the complete unsuitability of the measuring instrument - the scale. This situation may arise either due to “normative” pressure towards the generally accepted opinion, or due to the fact that the gradations (values) of the scale are not related to the distribution of a given property in the objects in question (irrelevant).
For example, if all respondents agree with the statement “it’s good when a construction tool is universal”, there is not a single “disagree” answer, then such a scale will not help differentiate respondents’ attitudes towards different types of construction tools.
Using part of the scale. Quite often it is discovered that only some part of the scale, some one of its poles with an adjacent more or less extensive zone, practically works.
Thus, if respondents are offered a scale for assessment that has positive and negative poles, in particular from +3 to – 3, then when assessing some obviously positive situation, respondents do not use negative assessments, but differentiate their opinions only with the help of positive ones. In order to calculate the value of the relative measurement error, the researcher must know definitely what metric the respondent uses - all seven gradations of the scale or only four positive ones. Thus, a measurement error of 1 point says little if we do not know what the actual variation in opinions is.
For questions that have qualitative gradations of answers, a similar requirement can be applied to each point of the scale: each of them must receive at least 5% of the answers, otherwise we consider this point of the scale to be invalid. The requirement of a 5% filling level for each gradation of the scale should not be considered as strictly mandatory; Depending on the objectives of the study, larger or smaller values of these levels may be put forward.
Uneven use of individual scale items. It happens that some value of a characteristic systematically falls out of the field of view of respondents, although neighboring gradations characterizing lower and higher degrees of expression of the characteristic have significant content.
A similar picture is observed in the case when the respondent is offered a scale that is too granular: being unable to operate with all gradations of the scale, the respondent selects only a few basic ones. For example, respondents often regard a ten-point scale as some modification of a five-point scale, assuming that “ten” corresponds to “five”, “eight” to “four”, “five” to “three”, etc. At the same time, basic ratings are used much more often , than others.
To identify these anomalies of uniform distribution on the scale, the following rule can be proposed: for a sufficiently large confidence probability (1-a > 0.99) and, therefore, within sufficiently wide limits, the filling of each value should not differ significantly from the average of neighboring fillings. What is the chi-square test used for?
Definition of blunders. During the measurement process, gross errors sometimes occur, the cause of which may be incorrect recording of source data, poor calculations, unskilled use of measuring instruments, etc. This is revealed in the fact that in the series of measurements there are data that differ sharply from the totality of all other values. To determine whether these values should be considered gross errors, a critical limit is set so that the probability that the extreme values exceed it would be small enough to correspond to some level of significance a. This rule is based on the fact that the appearance of excessively large values in a sample, although possible as a consequence of natural variability of values, is unlikely.
If it turns out that some extreme values of the population belong to it with a very low probability, then such values are recognized as gross errors and are excluded from further consideration. It is especially important to identify gross errors for small samples: without being excluded from the analysis, they significantly distort the parameters samples. For this purpose, special statistical criteria are used to determine gross errors.
So, the differentiating ability of a scale, as the first essential characteristic of its reliability, presupposes: ensuring sufficient spread of data; identifying the respondent’s actual use of the proposed scale length; analysis of individual “outliers” values; eliminating gross errors. Once the relative acceptability of the scales used in these aspects has been established, one should proceed to identifying the stability of measurement on this scale.
Measurement stability. There are several methods for assessing measurement stability: repeated testing; inclusion of equivalent questions in the questionnaire and dividing the sample into two parts.
Often, at the end of the survey, interviewers partially repeat it, saying: “When we finish our work, let’s briefly go over the questions of the questionnaire again so that I can check whether I wrote down everything correctly from your answers.” Of course, we are not talking about repeating all the questions, but only the critical ones. It must be remembered that if the time interval between testing and retesting is too short, then the respondent may simply remember the initial answers. If the interval is too long, then some real changes may occur.
Including equivalent questions in a questionnaire involves using questions on the same problem, but formulated differently, in one questionnaire. The respondent should perceive them as different questions. The main danger of this method lies in the degree of equivalence of questions; if this is not achieved, then the respondent answers different questions.
Dividing the sample into two parts is based on comparing answers to questions from two groups of respondents. It is assumed that the two groups are identical in composition and that the mean response scores for the two groups are very similar. All comparisons are made on a group basis only, so within-group comparisons cannot be made. For example, college students were surveyed using a modified five-point Likert scale regarding their future careers. The questionnaire included the statement: “I believe that a brilliant career awaits me.” Responses were summarized from “strongly disagree” (1 point) to “strongly agree” (5 points). The total sample of respondents was then divided into two groups and the average scores for these groups were calculated. The average score was the same for each group and equaled 3 points. These results gave grounds to consider the measurement reliable. When we analyzed the group responses more carefully, it turned out that in one group all students answered “both agree and disagree,” while in the other, 50% answered “strongly disagree,” and the other 50% answered “strongly agree.” As you can see, a deeper analysis showed that the answers are not identical.
Due to this drawback, this method of assessing measurement stability is the least popular.
We can talk about the high reliability of a scale only if repeated measurements using it on the same objects give similar results. If stability is checked on the same sample, then it is often sufficient to make two consecutive measurements with a certain time interval - such that this interval is not too long for a change in the object itself to be affected, but also not too small so that the respondent can remember from memory “pull up” the data of the second measurement to the previous one (i.e., its length depends on the object of study and ranges from two to three weeks).
There are various indicators for assessing the stability of measurements. Among them, the most commonly used is the mean square error.
Until now we have been talking about absolute errors, the size of which was expressed in the same units as the measured value itself. This does not allow us to compare measurement errors of different traits on different scales. Therefore, in addition to absolute ones, relative indicators of measurement errors are needed.
As an indicator for bringing the absolute error into relative form, you can use the maximum possible error in the scale under consideration, into which the arithmetic mean measurement errors are divided.
However, this indicator often “works poorly” due to the fact that the scale is not used throughout its entire length. Therefore, relative errors calculated from the actually used part of the scale are more indicative.
To increase the stability of measurement, it is necessary to find out the discriminating capabilities of the items of the scale used, which presupposes that respondents clearly record individual values: each assessment must be strictly separated from the neighboring one. In practice, this means that in successive samples respondents clearly repeat their assessments. Consequently, a small error should correspond to a high visibility of scale divisions.
But even with a small number of gradations, i.e., with a low level of discriminating capabilities of the scale, there may be low stability, and then the granularity of the scale should be increased. This happens when categorical answers “yes” and “no” are imposed on the respondent, but he would prefer less strict assessments. And therefore he chooses in repeated tests sometimes “yes”, sometimes “no”,
If a mixture of gradations is detected, one of two methods of enlarging the scale is used.
First way. In the final version, the granularity of the scale is reduced (for example, from a scale of 7 intervals they move to a scale of 3 intervals).
Second way. For presentation to the respondent, the previous granularity of the scale is retained and only during processing are the corresponding points enlarged.
The second method seems preferable, since, as a rule, a greater granularity of the scale encourages the respondent to a more active reaction. When processing data, information should be recoded in accordance with the analysis of the discriminative ability of the original scale.
Analysis of the stability of individual questions on the scale allows us to: a) identify poorly formulated questions and their inadequate understanding by different respondents; b) clarify the interpretation of the scale proposed for assessing a particular phenomenon, and identify a more optimal option for the fractionalization of the scale value.
Validity of measurement. Checking the validity of the scale is undertaken only after sufficient accuracy and stability of the measurement of the original data have been established.
The validity of measurement data is evidence of agreement between what is measured and what was intended to be measured. Some researchers prefer to proceed from the so-called available validity, i.e. validity in terms of the procedure used. For example, they believe that satisfaction with a product is the property that is contained in the answers to the question: “Are you satisfied with the product?” In serious marketing research, such a purely empirical approach may be unacceptable.
Let us dwell on possible formal approaches to determining the level of validity of the methodology. They can be divided into three groups: 1) construction of a typology in accordance with the objectives of the study based on several characteristics; 2) use of parallel data; 3) judicial procedures.
The first option cannot be considered a completely formal method - it is just some schematization of logical reasoning, the beginning of a justification procedure, which can be completed there, or can be supported by more powerful means.
The second option requires the use of at least two sources to identify the same property. Validity is determined by the degree of consistency of the relevant data.
In the latter case, we rely on the competence of the judges who are asked to determine whether we are measuring the property we need or something else.
The constructed typology consists in the use of control questions, which, together with the main ones, give a greater approximation to the content of the property being studied, revealing its various aspects.
For example, you can determine satisfaction with the car model you are using with a straightforward question: “Are you satisfied with your current car model?” Combining it with two other indirect ones: “Do you want to switch to another model?” and “Do you recommend your friend to buy this car model?” allows for more reliable differentiation of respondents. Next, a typology is carried out into five ordered groups from the most satisfied with the car to the least satisfied.
The use of parallel data involves the development of two equal methods for measuring a given characteristic. This makes it possible to establish the validity of the methods relative to each other, that is, to increase the overall validity by comparing two independent results.
Let's look at different ways to use this approach, and first of all, equivalent scales. Equivalent samples of characteristics are possible to describe the measurement of behavior, attitude, value orientation, i.e. some kind of installation. These samples form parallel scales, providing concurrent reliability.
We consider each scale as a way to measure a certain property and, depending on the number of parallel scales, we have a number of measurement methods. The respondent gives answers simultaneously on all parallel scales.
When processing this kind of data, two points should be clarified: 1) the consistency of the items on a separate scale; 2) consistency of assessments on different scales.
The first problem arises from the fact that response patterns do not present a perfect picture; the answers often contradict each other. Therefore, the question arises of what to take as the true value of the respondent’s assessment on this scale.
The second problem directly concerns the mapping of parallel data.
Consider an example of a failed attempt to improve the reliability of measuring the trait “satisfaction with a car” using three parallel ordinal scales. Here are two of them:
Fifteen judgments (in the order indicated on the left, at the beginning of each line) are presented to the respondent as a general list, and he must express his agreement or disagreement with each of them. Each judgment is assigned a score corresponding to its rank on the specified five-point scale (on the right). (For example, agreement with judgment 4 gives a score of “1”, agreement with judgment 11 – a score of “5”, etc.)
The method of presenting judgments as a list, considered here, makes it possible to analyze the scale items for consistency. When using ordered scales of names, it is usually assumed that the items making up the scale are mutually exclusive and the respondent will easily find the one that suits him.
A study of the distributions of answers shows that respondents express agreement with contradictory (from the point of view of the initial hypothesis) judgments. For example, on the “B” scale, 42 people out of 100 simultaneously agreed with judgments 13 and 12, that is, with two opposing judgments.
The presence of contradictory judgments in the answers on scale B leads to the need to consider the scale unacceptable.
This approach to increasing the reliability of a scale is very complex. Therefore, it can only be recommended when developing critical tests or techniques intended for mass use or panel studies.
It is possible to test one method on several respondents. If the method is reliable, then different respondents will give consistent information, but if their results are poorly consistent, then either the measurements are unreliable or the results of individual respondents cannot be considered equivalent. In the latter case, it is necessary to determine whether any group of results can be considered more trustworthy. The solution to this problem is all the more important if it is assumed that it is equally permissible to obtain information by any of the methods under consideration.
The use of parallel methods for measuring the same property faces a number of difficulties.
Firstly, it is unclear to what extent both methods measure the same quality of the object, and, as a rule, there are no formal criteria for testing such a hypothesis. Consequently, it is necessary to resort to a substantive (logical-theoretical) justification of a particular method.
Second, if parallel procedures are found to measure a common property (the data do not differ significantly), the question remains about the theoretical justification for using these procedures.
It must be admitted that the very principle of using parallel procedures turns out to be not a formal, but rather a substantive principle, the application of which is very difficult to substantiate theoretically.
One of the widespread approaches to establishing validity is the use of so-called judges, experts. Researchers ask a specific group of people to act as competent individuals. They are offered a set of features intended to measure the object being studied, and are asked to evaluate the correctness of attributing each of the features to this object. Joint processing of judges' opinions will make it possible to assign weights to features or, what is the same, scale ratings in the measurement of the object being studied. A set of features can be a list of individual judgments, characteristics of an object, etc.
Judging procedures are varied. They may be based on methods of paired comparisons, ranking, sequential intervals, etc.
The question of who should be considered judges is quite controversial. Judges selected as representatives of the population being studied must, in one way or another, represent its micromodel: according to the judges’ assessments, the researcher determines how adequately certain points of the survey procedure will be interpreted by respondents.
However, when selecting judges, a difficult question arises: what is the influence of the judges’ own attitudes on their assessments, because these attitudes may differ significantly from the attitudes of the subjects in relation to the same object.
In general, the solution to the problem is to: a) carefully analyze the composition of judges from the point of view of the adequacy of their life experience and signs of social status to the corresponding indicators of the surveyed population; b) identify the effect of individual deviations in judges' scores relative to the overall distribution of scores. Finally, it is necessary to evaluate not only the quality, but also the size of the sample population of judges.
On the one hand, this number is determined by consistency: if the consistency of judges' opinions is sufficiently high and, accordingly, the measurement error is small, the number of judges can be small. It is necessary to set the value of the permissible error and, based on it, calculate the required sample size.
If complete uncertainty of the object is detected, i.e. in the case when the opinions of the judges are distributed evenly across all assessment categories, no increase in the size of the sample of judges will save the situation and will not bring the object out of the state of uncertainty.
If the object is sufficiently uncertain, then a large number of gradations will only introduce additional interference into the work of judges and will not provide more accurate information. It is necessary to identify the stability of judges' opinions using repeated testing and, accordingly, narrow the number of gradations.
The choice of a particular method, method or technique for checking validity depends on many circumstances.
First of all, it should be clearly established whether any significant deviations from the planned measurement program are possible. If the research program sets strict limits, not one, but several methods should be used to check the validity of the data.
Secondly, it must be kept in mind that the levels of robustness and validity of data are closely interrelated. Unstable information, due to its lack of reliability according to this criterion, does not require too strict verification of validity. Sufficient robustness should be ensured, and then appropriate steps should be taken to clarify the boundaries of interpretation of the data (i.e., identify the level of validity).
Numerous experiments to identify the level of reliability allow us to conclude that in the process of developing measurement instruments, in terms of their reliability, the following sequence of main stages of work is advisable:
a) Preliminary control of the validity of methods for measuring primary data at the stage of testing the methodology. Here it is checked to what extent the information meets its intended purpose in essence and what are the limits of subsequent interpretation of the data. For this purpose, small samples of 10–20 observations are sufficient, followed by adjustments to the structure of the methodology.
b) The second stage is piloting the methodology and thoroughly checking the stability of the initial data, especially the selected indicators and scales. At this stage, a sample is needed that represents a micromodel of the real population of respondents.
c) During the same general aerobatics, all necessary operations related to checking the level of validity are carried out. The results of the analysis of pilot data lead to the improvement of the methodology, to the refinement of all its details and, ultimately, to the receipt of the final version of the methodology for the main study.
d) At the beginning of the main study, it is advisable to check the stability of the method used in order to calculate accurate indicators of its stability. Subsequent clarification of the boundaries of validity goes through the entire analysis of the results of the study itself.
Regardless of the reliability assessment method used, the researcher has four sequential steps to improve the reliability of the measurement results.
First, when measurement reliability is extremely low, some questions are simply discarded from the questionnaire, especially when the degree of reliability can be determined during the questionnaire development process.
Secondly, the researcher can “collapse” the scales and use fewer gradations. Let's say, the Likert scale in this case can only include the following gradations: “agree”, “disagree”, “I have no opinion”. This is usually done when the first step has been completed and when the examination has already been carried out.
Third, as an alternative to the second step or as an approach carried out after the second step, reliability assessment is carried out on a case-by-case basis. Let's say a direct comparison is made of respondents' answers during their initial and retests or with some equivalent answer. Answers from unreliable respondents are simply not taken into account in the final analysis. Obviously, if you use this approach without an objective assessment of the respondents’ reliability, then by throwing out “undesirable” answers, the research results can be adjusted to the desired ones.
Finally, after the first three steps have been used, the level of reliability of the measurements can be assessed. Typically, measurement reliability is characterized by a coefficient varying from zero to one, where one characterizes maximum reliability.
It is generally considered that the minimum acceptable level of reliability is characterized by figures of 0.65–0.70, especially if the measurements were taken for the first time.
It is obvious that in the process of various and numerous marketing research conducted by different companies, there was a consistent adaptation of measurement scales and methods for conducting them to the goals and objectives of specific marketing research. This makes it easier to solve the problems discussed in this section, and makes it rather necessary when conducting original marketing research.
The validity of measurements characterizes completely different aspects than the reliability of measurements. A measurement may be reliable but not valid. The latter characterizes the accuracy of measurements in relation to what exists in reality. For example, a respondent was asked about his annual income, which is less than $25,000. Reluctant to tell the interviewer the true figure, the respondent reported income as “more than $100,000.” When retested, he again named this figure, demonstrating a high level of reliability of the measurements. Falsehood is not the only reason for the low level of measurement reliability. You can also call it poor memory, poor knowledge of reality by the respondent, etc.
Let's consider another example that characterizes the difference between reliability and validity of measurements. Even an inaccurate watch will show the time at one hour twice a day, demonstrating high reliability. However, they can go very inaccurately, i.e. The time display will be unreliable.
The main direction of checking the reliability of measurements is to obtain information from various sources. This can be done in different ways. Here, first of all, the following should be noted.
We must strive to compose questions in such a way that their wording contributes to obtaining reliable answers. Further questions related to each other may be included in the questionnaire.
For example, the questionnaire contains a question about the extent to which the respondent likes a certain food product of a certain brand. And then it is asked how much of this product was purchased by the respondent over the last month. This question is aimed at checking the reliability of the answer to the first question.
Often two different methods or sources of information are used to assess the reliability of measurements. For example, after filling out written questionnaires, a number of respondents from the initial sample are additionally asked the same questions by telephone. Based on the similarity of the answers, the degree of their reliability is judged.
Sometimes, based on the same requirements, two samples of respondents are formed and their answers are compared to assess the degree of reliability.
Questions to check:
- What is measurement?
- How does objective measurement differ from subjective measurement?
- Describe the four scale characteristics.
- Define the four types of scales and indicate the types of information contained in each.
- What are the arguments for and against using neutral gradation in a symmetrical scale?
- What is a modified Likert scale and how do the life style scale and the semantic differential scale relate to it?
- What is the “halo effect” and how should a researcher control it?
- What components determine the content of the concept of “measurement reliability”?
- What disadvantages may the measurement scale used have?
- What methods for assessing measurement stability do you know?
- What approaches to assessing the level of validity of measurements do you know?
- How does measurement reliability differ from measurement validity?
- When should a researcher evaluate the reliability and validity of a measurement?
- Let's assume that you are engaged in marketing research and the owner of a private grocery store has approached you with a request to create a positive image of this store. Design a semantic differential scale to measure the relevant image dimensions of a given store. When performing this work you must do the following:
A. Conduct a brainstorming session to identify a set of measurable indicators.
b. Find the corresponding bipolar definitions.
V. Determine the number of gradations on the scale.
d. Choose a method to control the “halo effect”. - Design a measurement scale (justify the choice of scale, the number of gradations, the presence or absence of a neutral point or gradation; think about whether you are measuring what you planned to measure) for the following tasks:
A. A manufacturer of children's toys wants to know how preschoolers react to the video game “Sing with Us,” in which the child must sing along with the characters of the animated film.
b. A dairy products manufacturer is testing five new yoghurt flavors and wants to know how consumers rate the flavors in terms of sweetness, pleasantness, and richness.
References
- Burns Alvin C., Bush Ronald F. Marketing Research. New Jersey, Prentice Hall, 1995.
- Evlanov L.G. Theory and practice of decision making. M., Economics, 1984.
- Eliseeva I.I., Yuzbashev M.M. General theory of statistics. M., Finance and Statistics, 1996.
- A sociologist's workbook. M., Nauka, 1977.
We also recommend
 Delivery of documents by courier service accounting
Delivery of documents by courier service accounting
 Inventory of attachments in a valuable letter of Russian Post Sample of filling out an inventory of attachments
Inventory of attachments in a valuable letter of Russian Post Sample of filling out an inventory of attachments
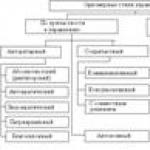 Economic indicators
Economic indicators
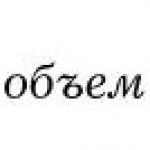 Types of scales used in semantic differential Semantic differential scale example
Types of scales used in semantic differential Semantic differential scale example
 History of the Russian Book Chamber The last issue of each year contains an index of articles and materials published in the magazine for the past year
History of the Russian Book Chamber The last issue of each year contains an index of articles and materials published in the magazine for the past year
 Didactic game “Which one, which one, which one?”
Didactic game “Which one, which one, which one?”