วิธีการพยากรณ์ทางคณิตศาสตร์ ความสำเร็จของวิทยาศาสตร์ธรรมชาติสมัยใหม่
วิธีการทางเศรษฐศาสตร์และคณิตศาสตร์ เมื่อใช้วิธีการทางเศรษฐศาสตร์และคณิตศาสตร์ โครงสร้างของแบบจำลองจะถูกกำหนดและตรวจสอบโดยการทดลอง ภายใต้เงื่อนไขที่อนุญาตให้สังเกตและวัดผลตามวัตถุประสงค์ได้
การกำหนดระบบของปัจจัยและโครงสร้างเหตุและผลของปรากฏการณ์ที่ศึกษาเป็นขั้นตอนเริ่มต้นของการสร้างแบบจำลองทางคณิตศาสตร์
วิธีการทางสถิติครอบครองสถานที่พิเศษในการพยากรณ์ วิธีการของสถิติทางคณิตศาสตร์และสถิติประยุกต์ใช้ในการวางแผนงานใดๆ เกี่ยวกับการพยากรณ์ ในการประมวลผลข้อมูลที่ได้รับทั้งโดยวิธีการที่เป็นธรรมชาติ และโดยการใช้วิธีการทางเศรษฐศาสตร์และคณิตศาสตร์ที่เหมาะสม โดยเฉพาะอย่างยิ่ง พวกเขาจะใช้เพื่อกำหนดจำนวนกลุ่มผู้เชี่ยวชาญ สัมภาษณ์พลเมือง ความถี่ในการรวบรวมข้อมูล และประเมินพารามิเตอร์ของแบบจำลองทางเศรษฐศาสตร์และคณิตศาสตร์เชิงทฤษฎี
แต่ละวิธีมีข้อดีและข้อเสีย วิธีการพยากรณ์ทั้งหมดช่วยเสริมซึ่งกันและกันและสามารถใช้ร่วมกันได้
วิธีสถานการณ์- เครื่องมือที่มีประสิทธิภาพสำหรับการจัดการคาดการณ์ ผสมผสานวิธีการเชิงคุณภาพและเชิงปริมาณ
สถานการณ์จำลองคือแบบจำลองของอนาคต ซึ่งอธิบายเหตุการณ์ที่เป็นไปได้ ซึ่งบ่งชี้ถึงความน่าจะเป็นของการดำเนินการ ภาพจำลองระบุปัจจัยหลักที่ต้องนำมาพิจารณาและระบุว่าปัจจัยเหล่านี้อาจส่งผลต่อเหตุการณ์ที่คาดการณ์ไว้อย่างไร ตามกฎแล้วจะมีการรวบรวมสถานการณ์ทางเลือกหลายสถานการณ์ สถานการณ์จำลองจึงเป็นลักษณะของอนาคตในการพยากรณ์เชิงสำรวจ ไม่ใช่คำจำกัดความของสถานะหนึ่งที่เป็นไปได้หรือที่ต้องการของอนาคต โดยปกติแล้ว ตัวแปรที่เป็นไปได้มากที่สุดของสถานการณ์จะถือเป็นฐานหนึ่ง โดยพิจารณาจากการตัดสินใจต่างๆ สถานการณ์จำลองเวอร์ชันอื่นๆ ซึ่งถือเป็นสถานการณ์ทางเลือก มีการวางแผนในกรณีที่ความเป็นจริงเริ่มเข้าถึงเนื้อหาในขอบเขตที่มากขึ้น ไม่ใช่เวอร์ชันพื้นฐานของสถานการณ์ สถานการณ์จำลองมักเป็นคำอธิบายเหตุการณ์และการประมาณการของตัวบ่งชี้และลักษณะเฉพาะในช่วงเวลาหนึ่ง ขั้นแรกใช้วิธีการเตรียมสถานการณ์เพื่อระบุผลลัพธ์ที่เป็นไปได้ของการปฏิบัติการทางทหาร ต่อมา การพยากรณ์สถานการณ์เริ่มใช้ในนโยบายเศรษฐกิจ และจากนั้นในการวางแผนองค์กรเชิงกลยุทธ์ ปัจจุบันเป็นกลไกการบูรณาการที่เป็นที่รู้จักมากที่สุดสำหรับการคาดการณ์กระบวนการทางเศรษฐกิจในตลาด สคริปต์เป็นวิธีที่มีประสิทธิภาพในการเอาชนะการคิดแบบเดิมๆ สถานการณ์จำลองคือการวิเคราะห์ปัจจุบันและอนาคตที่เปลี่ยนแปลงอย่างรวดเร็ว และการเตรียมการบังคับให้ต้องจัดการกับรายละเอียดและกระบวนการที่อาจพลาดไปเมื่อใช้วิธีการพยากรณ์เฉพาะแบบแยกส่วน ดังนั้น สถานการณ์จำลองจึงแตกต่างจากการคาดการณ์ทั่วไป เป็นเครื่องมือที่ใช้ในการกำหนดประเภทการพยากรณ์ที่ควรพัฒนาให้บรรยายอนาคตได้อย่างครบถ้วนเพียงพอโดยคำนึงถึงปัจจัยหลักทั้งหมด
การใช้การพยากรณ์สถานการณ์ในสภาวะตลาดให้:
เข้าใจสถานการณ์ดีขึ้น วิวัฒนาการของมัน;
การประเมินภัยคุกคามที่อาจเกิดขึ้น
การระบุโอกาส
การระบุทิศทางที่เป็นไปได้และเหมาะสมของกิจกรรม
เพิ่มระดับของการปรับตัวต่อการเปลี่ยนแปลงในสภาพแวดล้อมภายนอก
การพยากรณ์สถานการณ์สมมติเป็นวิธีที่มีประสิทธิภาพในการเตรียมการตัดสินใจตามแผนทั้งในองค์กรและในรัฐ
การวางแผนมีความเกี่ยวข้องอย่างใกล้ชิดกับการพยากรณ์ กระบวนการเหล่านี้ถูกแบ่งออกในระดับหนึ่งตามเงื่อนไข ดังนั้นสามารถใช้วิธีการเดียวกันหรือวิธีการที่เกี่ยวข้องอย่างใกล้ชิดในการวางแผนและการพยากรณ์ได้
วางแผนการตัดสินใจอนุมัติ แผนเป็นผลจากการตัดสินใจของฝ่ายบริหารที่ทำขึ้นบนพื้นฐานของทางเลือกในการวางแผนที่เป็นไปได้ การตัดสินใจของฝ่ายบริหารเป็นไปตามเกณฑ์บางประการ เมื่อใช้เกณฑ์เหล่านี้ ทางเลือกจะได้รับการประเมินในแง่ของการบรรลุเป้าหมายหนึ่งเป้าหมายขึ้นไป เกณฑ์สะท้อนเป้าหมายที่กำหนดโดยผู้มีอำนาจตัดสินใจ
การตัดสินใจตามเกณฑ์เดียวถือว่าง่าย และการตัดสินใจตามเกณฑ์หลายข้อถือว่าซับซ้อน เกณฑ์ซึ่งมีการกำหนดมาตราส่วนการให้คะแนนเชิงปริมาณหรือลำดับทำให้สามารถใช้วิธีทางคณิตศาสตร์ของการวิจัยการดำเนินงานเพื่อเตรียมการแก้ปัญหา
การตัดสินใจอนุมัติแผนไม่เพียงแต่จะซับซ้อนเนื่องจากหลายเกณฑ์เท่านั้น แต่ยังยากอย่างยิ่งเนื่องจากความไม่แน่นอน ข้อมูลที่จำกัด และความรับผิดชอบสูง ดังนั้น การตัดสินใจขั้นสุดท้ายเกี่ยวกับการอนุมัติแผนจะทำโดยการเลือกแบบศึกษาสำนึกและเข้าใจได้ง่ายจากทางเลือกที่เตรียมไว้ล่วงหน้าจำนวนจำกัด
วิธีการวางแผนจึงเป็นวิธีการเตรียมทางเลือกในการวางแผน หรืออย่างน้อยหนึ่งทางเลือกแผน เพื่อขออนุมัติจากผู้มีอำนาจตัดสินใจหรือหน่วยงาน
วิธีการสำหรับการเตรียมแผนตัวแปรตั้งแต่หนึ่งแผนขึ้นไปจะแตกต่างไปตามวิธีการที่ใช้สำหรับจัดทำแผน วิธีการ และเงื่อนไขสำหรับการดำเนินการตามแผน วัตถุการวางแผนที่เป็นไปได้
เช่นเดียวกับการพยากรณ์ การวางแผนจะขึ้นอยู่กับวิธีฮิวริสติกและคณิตศาสตร์ ในบรรดาวิธีทางคณิตศาสตร์ของการวิจัยการดำเนินงาน วิธีการวางแผนที่เหมาะสมที่สุดครอบครองสถานที่พิเศษ
วิธีการวางแผนที่เหมาะสมที่สุด ในการแก้ปัญหาการเตรียมตัวที่เหมาะสมที่สุด นั่นคือ ดีที่สุดตามเกณฑ์ที่กำหนด แผนงาน วิธีการเขียนโปรแกรมทางคณิตศาสตร์สามารถนำมาใช้ได้
งานของการเขียนโปรแกรมทางคณิตศาสตร์คือการค้นหาฟังก์ชันสูงสุดหรือต่ำสุดเมื่อมีข้อจำกัดเกี่ยวกับตัวแปร - องค์ประกอบของโซลูชัน ปัญหาทั่วไปจำนวนมากของการเขียนโปรแกรมทางคณิตศาสตร์เป็นที่ทราบกันดีอยู่แล้วสำหรับวิธีแก้ปัญหาที่มีการพัฒนาวิธีการอัลกอริธึมและโปรแกรมสำหรับคอมพิวเตอร์ที่มีประสิทธิภาพเช่น:
งานเกี่ยวกับองค์ประกอบของส่วนผสมซึ่งประกอบด้วยการกำหนดอาหารที่มีค่าใช้จ่ายขั้นต่ำและประกอบด้วยผลิตภัณฑ์ต่าง ๆ ที่มีปริมาณสารอาหารต่างกันตามเงื่อนไขเพื่อให้แน่ใจว่าเนื้อหาในอาหารไม่ต่ำกว่าระดับที่กำหนด
งานเกี่ยวกับแผนการผลิตที่เหมาะสมที่สุด ซึ่งประกอบด้วย การกำหนดแผนดีที่สุดสำหรับการผลิตสินค้าในแง่ของปริมาณการขายหรือกำไรที่มีทรัพยากรจำกัดหรือความสามารถในการผลิต
งานขนส่ง สาระสำคัญคือการเลือกแผนการขนส่งที่ให้ต้นทุนการขนส่งขั้นต่ำเมื่อดำเนินการตามปริมาณการส่งมอบให้กับผู้บริโภค ณ จุดต่างๆ ด้วยเส้นทางที่เป็นไปได้ที่แตกต่างกัน จากจุดต่างๆ ที่สต็อกหรือกำลังการผลิตมีจำกัด
วิธีทฤษฎีเกมสามารถใช้ในการวางแผนสำหรับสภาพอากาศที่ไม่แน่นอน ช่วงเวลาที่คาดว่าจะเกิดภัยพิบัติทางธรรมชาติ นี่คือ "เกม" ที่มี "ผู้เล่น" แบบพาสซีฟที่ทำหน้าที่โดยไม่คำนึงถึงแผนการของคุณ
วิธีการยังได้รับการพัฒนาเพื่อแก้ปัญหาทฤษฎีเกมด้วย "ผู้เล่น" ที่กระตือรือร้นซึ่งทำหน้าที่ตอบสนองต่อการกระทำของฝ่ายตรงข้าม นอกจากนี้ยังมีการพัฒนาวิธีการในการแก้ปัญหาซึ่งการกระทำของฝ่ายต่างๆ มีลักษณะเฉพาะด้วยกลยุทธ์บางอย่าง - ชุดของกฎการดำเนินการ การตัดสินใจเหล่านี้มีประโยชน์เมื่อร่างแผนเผชิญการต่อต้านจากคู่แข่ง ความหลากหลายในการกระทำของพันธมิตร
แนวทางแก้ไขปัญหาทฤษฎีเกมอาจขึ้นอยู่กับระดับความเสี่ยงที่เรายินดีจะยอมรับ หรือขึ้นอยู่กับการได้รับผลประโยชน์ที่รับประกันสูงสุด การแก้ปัญหาทฤษฎีเกมอย่างง่ายบางประเภทจะลดลงเหลือการแก้ปัญหาการโปรแกรมเชิงเส้น
มีการเผยแพร่เอกสารที่มีรายละเอียดและถูกต้องเพิ่มเติมเมื่อ
ในเดือนมีนาคม 2011 มีการเผยแพร่บันทึกย่อ "Five Ways to Improve Prediction Accuracy" ผู้เขียน Aleksey Skripchan มีประสิทธิภาพมากเรียบง่ายและเพียงพอในการพิจารณาการคาดการณ์ที่ต้องดำเนินการซึ่งเป็นส่วนหนึ่งของการตลาดและการวางแผน ฉายาของเขาฟังดูน่าสนใจในส่วนย่อย “ประโยชน์ของการพยากรณ์ที่ดีกว่า”:
การพยากรณ์กลายเป็นหางเสือที่ช่วยให้บริษัทอยู่บนเส้นทาง เปลี่ยนทิศทาง หรือนำทางน่านน้ำที่ไม่คุ้นเคยด้วยความมั่นใจ...
ฉันต้องการเพิ่มคำสองสามคำที่พูดไปแล้ว โดยหลักแล้ว ควรสังเกตว่าในบทความดังกล่าว เรากำลังพูดถึงการคาดการณ์ของผู้เชี่ยวชาญ ต้องแยกแยะ การพยากรณ์สองประเภท: ผู้เชี่ยวชาญและเป็นทางการ.
การพยากรณ์โดยผู้เชี่ยวชาญ
การพยากรณ์โดยผู้เชี่ยวชาญหมายถึงการสร้างค่านิยมในอนาคตโดยผู้เชี่ยวชาญ กล่าวคือ บุคคลที่มีความรู้ลึกซึ้งในด้านใดด้านหนึ่ง ในกรณีนี้ ผู้เชี่ยวชาญมักใช้เครื่องมือทางคณิตศาสตร์อย่างไรก็ตาม ในการพยากรณ์ประเภทนี้ เครื่องมือทางคณิตศาสตร์เป็นเพียงเครื่องมือช่วยคำนวณเท่านั้น พื้นฐานคือความรู้และสัญชาตญาณของผู้เชี่ยวชาญ ดังนั้นบางครั้งสิ่งเหล่านี้ วิธีการที่เรียกว่าสัญชาตญาณ.
การพยากรณ์โดยผู้เชี่ยวชาญจะใช้เมื่อวัตถุพยากรณ์ง่ายเกินไปหรือซับซ้อนจนไม่สามารถวิเคราะห์อิทธิพลของปัจจัยภายนอกได้. วิธีการพยากรณ์ของผู้เชี่ยวชาญไม่เกี่ยวข้องกับการพัฒนาแบบจำลองการคาดการณ์และสะท้อนถึงการตัดสินของผู้เชี่ยวชาญ (ผู้เชี่ยวชาญ) แต่ละคนเกี่ยวกับโอกาสในการพัฒนากระบวนการ วิธีการเหล่านี้รวมถึงวิธีการดังต่อไปนี้
- วิธีการประเมินโดยผู้เชี่ยวชาญ
- วิธีการเปรียบเทียบทางประวัติศาสตร์
- มองการณ์ไกลตามแบบแผน
- ตรรกะคลุมเครือ
- การสร้างแบบจำลองสถานการณ์ "จะเป็นอย่างไรถ้า"
การพยากรณ์แบบเป็นทางการเป็นการพยากรณ์ตาม แบบจำลองทางคณิตศาสตร์ซึ่งจับรูปแบบของกระบวนการที่ผลลัพธ์มีค่าในอนาคตของกระบวนการภายใต้การศึกษา. ค่อนข้างมาก ตัวอย่างเช่น ตามบทวิจารณ์จำนวนหนึ่ง ปัจจุบันมีโมเดลการคาดการณ์มากกว่า 100 คลาส แน่นอนว่าจำนวนคลาสทั่วไปของแบบจำลองที่ทำซ้ำในรูปแบบหนึ่งหรืออีกรูปแบบหนึ่งนั้นเล็กกว่ามากและสามารถลดลงเหลือโหลได้อย่างง่ายดาย
- แบบจำลองการถดถอย(แบบจำลองการถดถอย)
- แบบจำลองการถดถอยอัตโนมัติ( ,เออาร์)
- โมเดลโครงข่ายประสาทเทียม(โครงข่ายประสาทเทียม ANN)
- โมเดลการปรับให้เรียบแบบเอกซ์โพเนนเชียล( ,อีส)
- โมเดลตามเครือ Markov(โซ่มาร์คอฟ)
- ต้นไม้จำแนก-ถดถอย(ต้นไม้การจำแนกและการถดถอย , CART)
- สนับสนุนเครื่องเวกเตอร์(รองรับเวกเตอร์เครื่อง , SVM)
- อัลกอริทึมทางพันธุกรรม(อัลกอริทึมทางพันธุกรรม GA)
- รูปแบบฟังก์ชันการถ่ายโอน(ฟังก์ชั่นการโอน , TF)
- ตรรกะคลุมเครือ(ตรรกะคลุมเครือ FL)
- โมเดลพื้นฐาน
ผู้เขียนบทความเกี่ยวกับการคาดการณ์ในด้านการตลาดค่อนข้างตั้งข้อสังเกตว่า “ เช่นเดียวกับเครื่องมือใด ๆ คณิตศาสตร์อาจเป็นอันตรายได้ในมือของมือสมัครเล่น ในการตรวจสอบการคำนวณของคุณเอง คุณสามารถให้ผู้มีทักษะทางสถิติที่ดีมาวิเคราะห์ข้อมูลของคุณได้». แบบจำลองการพยากรณ์ทางคณิตศาสตร์ต้องการความสามารถที่พัฒนาแล้ว ไม่เพียงแต่ในวิชาคณิตศาสตร์เท่านั้น แต่ยังรวมถึงในการเขียนโปรแกรมด้วย การครอบครองแพ็คเกจทางสถิติที่ซับซ้อนเพื่อสร้างแบบจำลองที่แม่นยำและรวดเร็ว
การปรับปรุงความแม่นยำในการทำนาย
แน่นอนว่าทั้งสองประเภทของการคาดการณ์ที่พิจารณาแล้วมักจะทำงานร่วมกัน ตัวอย่างเช่น จากอัลกอริธึมที่ซับซ้อน ค่าในอนาคตของอนุกรมเวลาจะถูกคำนวณ จากนั้นผู้เชี่ยวชาญจะตรวจสอบตัวเลขเหล่านี้เพื่อความเพียงพอ ในขั้นตอนนี้ ผู้เชี่ยวชาญสามารถทำการปรับปรุงด้วยตนเองได้ ซึ่งหากมีคุณสมบัติสูง สามารถส่งผลดีต่อคุณภาพของการคาดการณ์ได้
โดยรวมแล้ว หากคุณต้องการปรับปรุงความแม่นยำของการคาดการณ์ของผู้เชี่ยวชาญในงานด้านการตลาด คุณต้องปฏิบัติตามคำแนะนำที่ให้ไว้ในบทความโดยตรง หากคุณต้องเผชิญกับงานในการปรับปรุงความแม่นยำของการพยากรณ์ผ่านแบบจำลองทางคณิตศาสตร์ที่ซับซ้อน รวดเร็ว และดำเนินการด้วยซอฟต์แวร์ คุณควรมองข้ามไป นั่นคือ การคาดการณ์ที่สร้างขึ้นบนพื้นฐานของชุดการคาดการณ์อิสระ อีกไม่นานฉันจะพูดถึง การคาดการณ์ฉันทามติรายละเอียดเพิ่มเติมในบล็อกนี้
1ในบทความจะมีการพิจารณาวิธีการพยากรณ์ทางคณิตศาสตร์แบบต่างๆ ในช่วงเวลาหนึ่ง ในตัวอย่างเฉพาะ รวมถึงการอนุมานอย่างง่าย วิธีการตามอัตราการเติบโต และการสร้างแบบจำลองทางคณิตศาสตร์ แสดงให้เห็นว่าการเลือกวิธีการขึ้นอยู่กับฐานการคาดการณ์ - ข้อมูลสำหรับช่วงเวลาก่อนหน้า
พยากรณ์
ชีวสถิติ
1. Afanasiev V.N. , Yuzbashev M.M. การวิเคราะห์และพยากรณ์อนุกรมเวลา: ตำราเรียน - ม.: การเงินและสถิติ, 2544. - 228 น.
2. Petri A. , Sabin K. สถิติภาพทางการแพทย์. - ม.: GEOTAR-MED, 2546. - 144 น.
3. Sadovnikova N.A. , Shmoylova R.A. การวิเคราะห์และพยากรณ์อนุกรมเวลา: หนังสือเรียน – ม.: เอ็ด. ศูนย์ EAOI, 2544. - 67 น.
โดยปกติ การพยากรณ์จะเข้าใจว่าเป็นกระบวนการของการทำนายอนาคตโดยอาศัยข้อมูลบางส่วนในอดีต กล่าวคือ ศึกษาการพัฒนาปรากฏการณ์ที่น่าสนใจในเวลา จากนั้นค่าที่ทำนายจะถือเป็นฟังก์ชันของเวลา y=f(t) อย่างไรก็ตาม การพยากรณ์โรคประเภทอื่น ๆ ก็มีการพิจารณาในทางการแพทย์เช่นกัน: การทำนายการวินิจฉัย ค่าการวินิจฉัยของการทดสอบใหม่ การเปลี่ยนแปลงในปัจจัยหนึ่งภายใต้อิทธิพลของอีกปัจจัยหนึ่ง เป็นต้น
บทความนี้มีวัตถุประสงค์เพื่อนำเสนอวิธีการพยากรณ์และแนวทางการใช้ทางการแพทย์ที่ถูกต้อง
วัสดุและวิธีการวิจัย
วิธีการพยากรณ์ต่อไปนี้ได้รับการพิจารณาในบทความ: วิธีการคาดการณ์อย่างง่าย, วิธีค่าเฉลี่ยเคลื่อนที่, วิธีการปรับให้เรียบแบบเอ็กซ์โปเนนเชียล, วิธีการเติบโตสัมบูรณ์เฉลี่ย, วิธีอัตราการเติบโตเฉลี่ย, วิธีการพยากรณ์ตามแบบจำลองทางคณิตศาสตร์
ผลการวิจัยและการอภิปราย
ตามที่ระบุไว้แล้ว การคาดการณ์จะขึ้นอยู่กับข้อมูลบางส่วนจากอดีต (ฐานการคาดการณ์) ก่อนเลือกวิธีการพยากรณ์ อย่างน้อยในเชิงคุณภาพควรประเมินการเปลี่ยนแปลงของปริมาณที่ศึกษาในช่วงเวลาก่อนหน้า กราฟที่นำเสนอ (รูปที่ 1) แสดงว่าสามารถแตกต่างกันได้
ข้าว. 1. ตัวอย่างพลวัตของปริมาณที่ศึกษา
ในกรณีแรก (พล็อต A) จะสังเกตเห็นความเสถียรสัมพัทธ์โดยมีความผันผวนเล็กน้อยรอบๆ ค่าเฉลี่ย ในกรณีที่สอง (กราฟ B) ไดนามิกจะเพิ่มขึ้นเป็นเส้นตรง ในกรณีที่สาม (กราฟ C) การพึ่งพาเวลาจะไม่เป็นเชิงเส้นและเป็นเลขชี้กำลัง กรณีที่สี่ (แผนภูมิ D) เป็นตัวอย่างของความผันผวนที่ซับซ้อนซึ่งมีองค์ประกอบหลายอย่าง
วิธีการพยากรณ์ระยะสั้นที่พบบ่อยที่สุด (ช่วงเวลา 1-3) คือการอนุมาน ซึ่งประกอบด้วยการขยายรูปแบบก่อนหน้าไปสู่อนาคต การใช้การคาดคะเนในการพยากรณ์ขึ้นอยู่กับสมมติฐานดังต่อไปนี้:
พัฒนาการของปรากฏการณ์ภายใต้การศึกษาโดยรวมมีเส้นโค้งเรียบ
แนวโน้มทั่วไปในการพัฒนาปรากฏการณ์ทั้งในอดีตและปัจจุบันจะไม่เกิดการเปลี่ยนแปลงครั้งใหญ่ในอนาคต
วิธีแรกของวิธีการอนุมานอย่างง่ายคือวิธีเฉลี่ยแบบอนุกรม ในวิธีนี้ ระดับที่คาดการณ์ไว้ของปริมาณที่ศึกษาจะเท่ากับค่าเฉลี่ยของระดับของอนุกรมของปริมาณนี้ในอดีต วิธีนี้ใช้หากระดับเฉลี่ยไม่มีแนวโน้มที่จะเปลี่ยนแปลง หรือการเปลี่ยนแปลงนี้ไม่มีนัยสำคัญ (ไม่มีแนวโน้มที่ชัดเจน รูปที่ 1 กราฟ A)
โดยที่ yprog คือระดับที่คาดการณ์ไว้ของค่าที่ศึกษา yi - ค่าของระดับ i-th; n - ฐานพยากรณ์
ในแง่หนึ่ง ส่วนของอนุกรมเวลาที่ครอบคลุมโดยการสังเกตสามารถเปรียบได้กับกลุ่มตัวอย่าง ซึ่งหมายความว่าผลการคาดการณ์จะเป็นแบบคัดเลือก ซึ่งสามารถระบุช่วงความเชื่อมั่นได้
ค่าเบี่ยงเบนมาตรฐานของอนุกรมเวลาอยู่ที่ไหน tα -การทดสอบของนักเรียนสำหรับระดับนัยสำคัญที่กำหนดและจำนวนองศาอิสระ (n-1)
ตัวอย่าง. ในตาราง. 1 แสดงข้อมูลของอนุกรมเวลา y(t) คำนวณค่าที่ทำนายไว้ของ y ณ เวลา t =13 โดยใช้วิธีอนุกรมเฉลี่ย
ตารางที่ 1
ข้อมูลอนุกรมเวลา y(t)
|
(80+98+94+103)/4 |
|||
|
(80+98+94+103+84)/5 |
|||
|
(80+98+94+103+84+115)/6 |
|||
|
(80+98+94+103+84+115+98)/7 |
|||
|
(80+98+94+103+84+115+98+113)/8 |
|||
|
(80+98+94+103+84+115+98+113+114)/9 |
|||
|
(80+98+94+103+84+115+98+113+114+87)/10 |
|||
|
(80+98+94+103+84+115+98+113+114+87+107)/11 |
|||
|
(80+98+94+103+84+115+98+113+114+87+107+85)/12 |
ซีรีย์ดั้งเดิมและเรียบแสดงในรูปที่ 2 การคำนวณ y - ในตาราง 2.

ข้าว. 2. ชุดเริ่มต้นและเรียบ
ตารางที่ 2
ช่วงความเชื่อมั่นสำหรับการคาดการณ์ ณ เวลา t =13
วิธีค่าเฉลี่ยเคลื่อนที่เป็นวิธีการคาดการณ์ระยะสั้นโดยอิงตามขั้นตอนการปรับระดับของค่าที่ศึกษาให้ราบเรียบ (การกรอง) ส่วนใหญ่จะใช้ฟิลเตอร์ป้องกันรอยหยักเชิงเส้นที่มีช่วง m นั่นคือ
![]() .
.
ช่วงความเชื่อมั่น
ค่าเบี่ยงเบนมาตรฐานของอนุกรมเวลาอยู่ที่ไหน tα - การทดสอบของนักเรียนสำหรับระดับนัยสำคัญที่กำหนดและจำนวนองศาอิสระ (n-1)
ตัวอย่าง. ในตาราง. 3 แสดงข้อมูลของอนุกรมเวลา y(t) คำนวณค่าที่คาดการณ์ไว้ y ณ เวลา t =13 โดยใช้วิธีค่าเฉลี่ยเคลื่อนที่ด้วยช่วงการปรับให้เรียบ m=3
ซีรีย์ดั้งเดิมและเรียบแสดงในรูปที่ 3 การคำนวณ y - ในตาราง 4.
ตารางที่ 3
ข้อมูลอนุกรมเวลา y(t)

ข้าว. 3. ซีรีย์เริ่มต้นและเรียบ
ตารางที่ 4
ค่าพยากรณ์ y
วิธีการปรับให้เรียบแบบเอกซ์โปเนนเชียลเป็นวิธีที่ใช้ค่าของระดับก่อนหน้าซึ่งถ่ายด้วยน้ำหนักที่แน่นอนในกระบวนการปรับระดับแต่ละระดับ เมื่อคุณเคลื่อนออกจากระดับหนึ่ง น้ำหนักของการสังเกตนี้จะลดลง ค่าความเรียบของระดับ ณ เวลา t ถูกกำหนดโดยสูตร
โดยที่ St คือค่าที่ปรับให้เรียบในปัจจุบัน yt - มูลค่าปัจจุบันของซีรี่ส์ดั้งเดิม St - 1 - ค่าที่ปรับให้เรียบก่อนหน้า α - พารามิเตอร์การปรับให้เรียบ
S0 นำมาเท่ากับค่าเฉลี่ยเลขคณิตของค่าสองสามค่าแรกของชุดข้อมูล
ในการคำนวณ α เสนอสูตรต่อไปนี้
ไม่มีความเห็นเป็นเอกฉันท์ในการเลือก α ปัญหาของการเพิ่มประสิทธิภาพแบบจำลองนี้ยังไม่ได้รับการแก้ไข วรรณกรรมบางฉบับแนะนำให้เลือก 0.1 ≤ α ≤ 0.3
พยากรณ์คำนวณดังนี้
![]() .
.
ช่วงความเชื่อมั่น
ตารางที่ 5
ข้อมูลอนุกรมเวลา y(t)
|
0.3×80+(1-0.3)×90.7 |
|||
|
0.3×98+(1-0.3)×87.5 |
|||
|
0.3×94+(1-0.3)×90.6 |
|||
|
0.3⋅103+(1-0.3)×91.6 |
|||
|
0.3×84+(1-0.3)×95 |
|||
|
0.3⋅115+(1-0.3)×91.7 |
|||
|
0.3×98+(1-0.3)×98.7 |
|||
|
0.3⋅113+(1-0.3)×98.5 |
|||
|
0,3⋅114+(1-0,3) ⋅102,8 |
|||
|
0.3×87+(1-0.3) ⋅106.2 |
|||
|
0,3⋅107+(1-0,3) ⋅100,4 |
|||
|
0.3×85+(1-0.3) ⋅102.4 |
|||
|
97.2+0.3× (85-97.2) |
ซีรีย์ดั้งเดิมและเรียบแสดงในรูปที่ 4 การคำนวณ y - ในตาราง 6.

ข้าว. 4. ซีรี่ส์เริ่มต้นและเรียบ
ตารางที่ 6
ค่าพยากรณ์ y ณ เวลา t =11
วิธีการพยากรณ์ถัดไปคือวิธีการของการเติบโตแบบสัมบูรณ์เฉลี่ยซึ่งระดับที่คาดการณ์ไว้ของปริมาณที่ศึกษาจะเปลี่ยนแปลงไปตามอัตราการเติบโตสัมบูรณ์เฉลี่ยของปริมาณนี้ในอดีต วิธีนี้ใช้ในกรณีที่แนวโน้มทั่วไปในไดนามิกเป็นเส้นตรง (สำหรับกรณีที่แสดงในรูปที่ 1 กราฟ B)
ที่ไหน ; y0 - ระดับพื้นฐานของการคาดการณ์ถูกเลือกเป็นค่าเฉลี่ยของค่าสองสามค่าสุดท้ายของชุดข้อมูลดั้งเดิม - เพิ่มขึ้นแน่นอนโดยเฉลี่ยในระดับของซีรีส์ l คือจำนวนช่วงการคาดการณ์
ค่าเฉลี่ยของค่าสุดท้ายของชุดข้อมูลสูงสุดสามค่าจะถูกนำมาเป็นระดับฐาน
ตารางที่ 7
ข้อมูลอนุกรมเวลา y(t)
|
พยากรณ์ = y0+Δl |
||||
|
(60+75+70)/3=68,3 |
||||
|
(75+70+103)/3=82,7 |
||||
|
(70+103+100)/3=91 |
||||
|
(103+100+115)/3=106 |
||||
|
(100+115+125)/3=113,3 |
||||
|
(115+125+113)/3=117,7 |
||||
|
(125+113+138)/3=125,3 |
||||
|
(113+138+136)/3=129 |
||||
|
(138+136+145)/3=139,7 |
||||
|
(136+145+150)/3=143,7 |
143,7+8,2⋅1=151,9 |
|||
|
143,7+8,2⋅2=160,1 |
||||
|
143,7+8,2⋅3=168,3 |
||||
ซีรีย์ดั้งเดิมและเรียบแสดงในรูปที่ ห้า.

ข้าว. 5. ซีรีย์เริ่มต้นและเรียบ
วิธีอัตราการเติบโตเฉลี่ย
ระดับที่คาดการณ์ไว้ของปริมาณที่ศึกษาจะเปลี่ยนแปลงไปตามอัตราการเติบโตเฉลี่ยของปริมาณนี้ในอดีต วิธีนี้ใช้หากแนวโน้มโดยรวมในไดนามิกมีลักษณะเฉพาะด้วยเส้นโค้งเลขชี้กำลังหรือเส้นเลขชี้กำลัง (รูปที่ 1B)
อัตราการเติบโตเฉลี่ยในอดีตอยู่ที่ใด l คือจำนวนช่วงการทำนาย
ค่าประมาณการพยากรณ์จะขึ้นอยู่กับทิศทางที่ระดับฐาน y0 เบี่ยงเบนจากแนวโน้มหลัก (แนวโน้ม) ดังนั้นจึงแนะนำให้คำนวณ y0 เป็นค่าเฉลี่ยของค่าสองสามค่าสุดท้ายของชุดข้อมูล
ตารางที่ 8
ข้อมูลอนุกรมเวลา y(t)
|
62,5⋅1,081 = 67,7 |
||||
|
(70/60)1/2 =1,08 |
65⋅1,081 = 70,2 |
|||
|
(65+70+68)/3=67,7 |
(68/60)1/3 =1,04 |
67,7⋅1,041 =70,5 |
||
|
(70+68+82)/3=73,3 |
(82/60)1/4 =1,08 |
73,3⋅1,081 =79,3 |
||
|
(68+82+80)/3=76,7 |
(80/60)1/5 =1,06 |
76,7⋅1,061 =81,2 |
||
|
(82+80+95)/3=85,7 |
(95/60)1/6 =1,08 |
85,7⋅1,081 =92,5 |
||
|
(80+95+113)/3=96 |
(113/60)1/7 =1,09 |
96⋅1,091 =105,1 |
||
|
(95+113+135)/3=114,3 |
(135/60)1/8 =1,11 |
114,3⋅1,111 =126,5 |
||
|
(113+135+140)/3=129,3 |
(140/60)1/9 =1,10 |
129,3⋅1,11 =142,1 |
||
|
(135+140+168)/3=147,7 |
(168/60)1/10 =1,11 |
147,7⋅1,111 =163,7 |
||
|
(140+168205)/3=171 |
(205/60)1/11 =1,12 |
171⋅1,121 =191,2 |
||
|
171⋅1,122 =213,8 |
||||
|
171⋅1,123 =239,1 |
ซีรีย์ดั้งเดิมและเรียบแสดงในรูปที่ 6.

ข้าว. 6. ซีรี่ส์เริ่มต้นและเรียบ
จนถึงปัจจุบัน วิธีการพยากรณ์ที่ใช้บ่อยที่สุดคือการค้นหานิพจน์เชิงวิเคราะห์ (สมการ) ของแนวโน้ม แนวโน้มของปรากฏการณ์ที่คาดคะเนเป็นแนวโน้มหลักของอนุกรมเวลา โดยปราศจากอิทธิพลแบบสุ่มในระดับหนึ่ง
การพัฒนาการคาดการณ์ประกอบด้วยการกำหนดประเภทของฟังก์ชันการประมาณค่า y=f(t) ซึ่งแสดงการพึ่งพาอาศัยของค่าที่ศึกษาตามเวลาโดยอิงจากข้อมูลที่สังเกตได้ในเบื้องต้น ขั้นตอนแรกคือการเลือกประเภทฟังก์ชันที่เหมาะสมที่สุดซึ่งให้คำอธิบายที่ดีที่สุดของแนวโน้ม การพึ่งพาที่ใช้บ่อยที่สุดคือ:
เชิงเส้น ;
พาราโบลา ;
ฟังก์ชันเลขชี้กำลัง ;
ปัญหาในการหาสัมประสิทธิ์ของฟังก์ชันเชิงเส้นและการพยากรณ์ตามค่าสัมประสิทธิ์ได้รับการพิจารณาในส่วนสถิติ "การวิเคราะห์การถดถอย" หากรูปร่างของเส้นโค้งที่อธิบายแนวโน้มไม่เป็นเชิงเส้น ภาระงานในการประมาณค่าฟังก์ชัน y=f(t) จะซับซ้อนมากขึ้น และในกรณีนี้ จำเป็นต้องมีนักชีวสถิติในการวิเคราะห์และใช้โปรแกรมคอมพิวเตอร์เพื่อสถิติ การประมวลผลข้อมูล
ในกรณีส่วนใหญ่ อนุกรมเวลาเป็นเส้นโค้งที่ซับซ้อนซึ่งสามารถแสดงเป็นผลรวมหรือผลคูณของแนวโน้ม ฤดูกาล วัฏจักร และส่วนประกอบแบบสุ่ม
แนวโน้มคือการเปลี่ยนแปลงอย่างราบรื่นในกระบวนการเมื่อเวลาผ่านไป และเกิดจากการกระทำของปัจจัยระยะยาว ผลกระทบตามฤดูกาลสัมพันธ์กับการมีอยู่ของปัจจัยที่กระทำกับช่วงเวลาที่กำหนดไว้ล่วงหน้า (เช่น ฤดูกาล รอบดวงจันทร์) องค์ประกอบที่เป็นวัฏจักรอธิบายช่วงเวลาที่ยาวนานของการขึ้นและลงสัมพัทธ์ และประกอบด้วยวัฏจักรของระยะเวลาและแอมพลิจูดที่แปรผันได้ (เช่น โรคระบาดบางชนิดมีลักษณะเป็นวัฏจักรที่ยาวนาน) องค์ประกอบสุ่มของชุดข้อมูลสะท้อนผลกระทบของปัจจัยสุ่มจำนวนมาก และสามารถมีโครงสร้างที่หลากหลาย
บทสรุป
วิธีการอนุมานอย่างง่าย วิธีการของค่าเฉลี่ยเคลื่อนที่ วิธีการปรับให้เรียบแบบเอ็กซ์โปเนนเชียลนั้นง่ายที่สุด และในขณะเดียวกันก็เป็นการประมาณค่ามากที่สุด - สามารถมองเห็นได้จากช่วงความเชื่อมั่นที่กว้างในตัวอย่างที่ให้ไว้ มีการสังเกตข้อผิดพลาดในการคาดการณ์ขนาดใหญ่ในกรณีที่ระดับความผันผวนรุนแรง ควรสังเกตว่าการใช้วิธีการเหล่านี้เป็นสิ่งผิดกฎหมาย หากมีแนวโน้มขึ้น (หรือลง) ที่ชัดเจนในอนุกรมเวลาเริ่มต้น อย่างไรก็ตาม สำหรับการคาดการณ์ระยะสั้น การใช้งานนั้นสมเหตุสมผล
การวิเคราะห์องค์ประกอบทั้งหมดของอนุกรมเวลาและการพยากรณ์โดยอิงจากองค์ประกอบนั้นไม่ใช่งานเล็กน้อย แต่ให้พิจารณาในส่วนสถิติ "การวิเคราะห์อนุกรมเวลา" และต้องมีการฝึกอบรมพิเศษ
ลิงค์บรรณานุกรม
Koichubekov B.K. , Sorokina M.A. , Mkhitaryan K.E. วิธีการทางคณิตศาสตร์ของการทำนายในการแพทย์ // ความสำเร็จของวิทยาศาสตร์ธรรมชาติสมัยใหม่ - 2557. - ลำดับที่ 4 - หน้า 29-36;URL: http://natural-sciences.ru/ru/article/view?id=33316 (วันที่เข้าถึง: 03/30/2019) เราขอนำเสนอนิตยสารที่จัดพิมพ์โดยสำนักพิมพ์ "Academy of Natural History" 23 เมษายน 2556 เวลา 11:08 น.
การจำแนกวิธีการพยากรณ์และแบบจำลอง
- คณิตศาสตร์
- กวดวิชา
ฉันทำการคาดการณ์อนุกรมเวลามานานกว่า 5 ปี ปีที่แล้วฉันปกป้องวิทยานิพนธ์ของฉันในหัวข้อ " แบบจำลองการคาดการณ์อนุกรมเวลาจากตัวอย่างความคล้ายคลึงสูงสุด” อย่างไรก็ตาม หลังจากการป้องกัน มีคำถามเหลืออยู่ค่อนข้างน้อย นี่คือหนึ่งในนั้น - การจำแนกประเภททั่วไปของวิธีการพยากรณ์และแบบจำลอง.
โดยปกติในงานของนักเขียนทั้งในประเทศและที่พูดภาษาอังกฤษ พวกเขาจะไม่ถามตัวเองถึงคำถามเกี่ยวกับการจำแนกประเภทของวิธีการพยากรณ์และแบบจำลอง แต่เพียงแค่ระบุรายการเหล่านั้น แต่สำหรับฉันแล้วดูเหมือนว่าวันนี้พื้นที่นี้ได้เติบโตและขยายออกไปมากจนแม้ว่าจะจำเป็นต้องจำแนกประเภททั่วไปที่สุดก็ตาม ด้านล่างนี้เป็นการจำแนกประเภททั่วไปของฉันเอง
อะไรคือความแตกต่างระหว่างวิธีการพยากรณ์และแบบจำลอง?
วิธีการทำนายแสดงถึงลำดับของการกระทำที่ต้องทำเพื่อให้ได้แบบจำลองการคาดการณ์ เมื่อเปรียบเทียบกับการปรุงอาหาร วิธีการคือลำดับของการกระทำตามจานที่เตรียม - นั่นคือการคาดการณ์
แบบจำลองการทำนายเป็นตัวแทนการทำงานที่อธิบายกระบวนการภายใต้การศึกษาอย่างเพียงพอและเป็นพื้นฐานสำหรับการได้รับคุณค่าในอนาคต ในการเปรียบเทียบการทำอาหารแบบเดียวกัน แบบจำลองมีรายการส่วนผสมและอัตราส่วนซึ่งจำเป็นสำหรับอาหารของเรา - การคาดการณ์
การผสมผสานของวิธีการและรูปแบบเป็นสูตรที่สมบูรณ์!
ปัจจุบัน เป็นเรื่องปกติที่จะใช้ตัวย่อภาษาอังกฤษสำหรับชื่อของทั้งสองรุ่นและเมธอด ตัวอย่างเช่น มีแบบจำลองการคาดการณ์ค่าเฉลี่ยเคลื่อนที่แบบถดถอยอัตโนมัติแบบบูรณาการ (ARIMAX) ที่มีชื่อเสียง โมเดลนี้และวิธีการที่เกี่ยวข้องกันมักจะเรียกว่า ARIMAX และบางครั้งโมเดล Box-Jenkins (วิธีการ) หลังจากผู้เขียน
ก่อนอื่นเราจัดประเภทวิธีการ
หากมองใกล้จะเข้าใจได้อย่างรวดเร็วว่าแนวคิดของ " วิธีการพยากรณ์"แนวคิดที่กว้างขึ้น" แบบจำลองการทำนาย". ในเรื่องนี้ ในขั้นตอนแรกของการจัดประเภท วิธีการมักจะแบ่งออกเป็นสองกลุ่ม: สัญชาตญาณและเป็นทางการ
หากเราจำการเปรียบเทียบการทำอาหารของเราได้ แม้กระทั่งที่นั่น เราก็สามารถแบ่งสูตรทั้งหมดออกเป็นส่วนๆ ได้ กล่าวคือ เขียนตามจำนวนส่วนผสมและวิธีการเตรียม และโดยสัญชาตญาณ นั่นคือ ไม่มีการบันทึกที่ไหนและได้มาจากประสบการณ์ ผู้เชี่ยวชาญด้านการทำอาหาร เมื่อใดที่เราไม่ใช้ใบสั่งยา? เมื่อจานเป็นเรื่องง่ายมาก: ทอดมันฝรั่งหรือเกี๊ยวต้ม คุณไม่จำเป็นต้องมีสูตร เมื่อไหร่ที่เราไม่ใช้สูตร? เมื่อเราต้องการประดิษฐ์สิ่งใหม่!
วิธีการพยากรณ์ที่ใช้งานง่ายจัดการกับคำตัดสินและการประเมินของผู้เชี่ยวชาญ จนถึงปัจจุบัน มักใช้ในด้านการตลาด เศรษฐศาสตร์ การเมือง เนื่องจากระบบซึ่งต้องคาดการณ์พฤติกรรม มีความซับซ้อนมาก และไม่สามารถอธิบายทางคณิตศาสตร์ได้ หรือเรียบง่ายมาก และไม่ต้องการคำอธิบายดังกล่าว รายละเอียดเกี่ยวกับวิธีการดังกล่าวสามารถพบได้ใน
วิธีการเป็นทางการ- วิธีการพยากรณ์ที่อธิบายไว้ในวรรณคดีซึ่งเป็นผลมาจากการสร้างแบบจำลองการคาดการณ์นั่นคือพวกเขากำหนดการอ้างอิงทางคณิตศาสตร์ที่ช่วยให้คุณคำนวณมูลค่าในอนาคตของกระบวนการซึ่งก็คือการพยากรณ์
ในความคิดของฉันการจำแนกประเภททั่วไปของวิธีการพยากรณ์ในความคิดของฉันสามารถทำได้
ต่อไป เราทำการจำแนกประเภททั่วไปของโมเดล
ที่นี่จำเป็นต้องดำเนินการจำแนกประเภทของแบบจำลองการคาดการณ์ ในระยะแรก โมเดลควรแบ่งออกเป็นสองกลุ่ม: โมเดลโดเมนและโมเดลอนุกรมเวลา

โมเดลโดเมน- แบบจำลองการพยากรณ์ทางคณิตศาสตร์ดังกล่าวสำหรับการสร้างซึ่งใช้กฎหมายของสาขาวิชา ตัวอย่างเช่น แบบจำลองที่ใช้ในการพยากรณ์อากาศประกอบด้วยสมการพลศาสตร์ของไหลและอุณหพลศาสตร์ การพยากรณ์การพัฒนาประชากรสร้างขึ้นจากแบบจำลองที่สร้างจากสมการเชิงอนุพันธ์ การทำนายระดับน้ำตาลในเลือดของผู้ป่วยเบาหวานนั้นทำบนพื้นฐานของระบบสมการเชิงอนุพันธ์ กล่าวโดยย่อ โมเดลดังกล่าวใช้การขึ้นต่อกันที่เฉพาะเจาะจงกับสาขาวิชาเฉพาะ โมเดลดังกล่าวมีลักษณะเฉพาะตามแนวทางการพัฒนาของแต่ละบุคคล
รุ่นอนุกรมเวลา- แบบจำลองการพยากรณ์ทางคณิตศาสตร์ที่พยายามค้นหาการพึ่งพามูลค่าในอนาคตจากอดีตภายในกระบวนการเอง และคำนวณการคาดการณ์จากการพึ่งพาอาศัยนี้ โมเดลเหล่านี้เป็นแบบสากลสำหรับสาขาวิชาต่างๆ กล่าวคือ รูปแบบทั่วไปจะไม่เปลี่ยนแปลงขึ้นอยู่กับลักษณะของอนุกรมเวลา เราสามารถใช้โครงข่ายประสาทเทียมในการทำนายอุณหภูมิของอากาศ จากนั้นจึงนำแบบจำลองที่คล้ายกันไปใช้กับโครงข่ายประสาทเทียมเพื่อทำนายดัชนีหุ้น นี่เป็นแบบจำลองทั่วไป เช่น น้ำเดือด ซึ่งถ้าคุณโยนผลิตภัณฑ์ลงไป มันจะเดือดโดยไม่คำนึงถึงลักษณะของผลิตภัณฑ์
การจำแนกแบบจำลองอนุกรมเวลา
สำหรับฉันแล้ว ดูเหมือนว่าเป็นไปไม่ได้ที่จะสร้างการจำแนกประเภททั่วไปของโมเดลโดเมน: จำนวนโดเมน, โมเดลมากมาย! อย่างไรก็ตาม แบบจำลองอนุกรมเวลาช่วยให้การแบ่งแบบง่าย ๆ เป็นเรื่องง่าย โมเดลอนุกรมเวลาสามารถแบ่งออกเป็นสองกลุ่ม: สถิติและโครงสร้าง

ใน แบบจำลองทางสถิติการพึ่งพามูลค่าในอนาคตในอดีตจะได้รับในรูปของสมการบางอย่าง ซึ่งรวมถึง:
- ตัวแบบการถดถอย (การถดถอยเชิงเส้น การถดถอยแบบไม่เชิงเส้น);
- แบบจำลองการถดถอยอัตโนมัติ (ARIMAX, GARCH, ARDLM);
- แบบจำลองการปรับให้เรียบแบบเอ็กซ์โพเนนเชียล
- แบบจำลองตามตัวอย่างความคล้ายคลึงกันสูงสุด
- ฯลฯ
ใน แบบจำลองโครงสร้างการพึ่งพาอาศัยกันของมูลค่าในอนาคตในอดีตจะได้รับในรูปแบบของโครงสร้างและกฎบางอย่างสำหรับการเคลื่อนไปตามนั้น ซึ่งรวมถึง:
- โมเดลโครงข่ายประสาทเทียม
- แบบจำลองตามเครือ Markov;
- แบบจำลองตามแผนผังการจำแนก-การถดถอย
- ฯลฯ
สำหรับทั้งสองกลุ่ม ฉันได้ระบุรูปแบบการพยากรณ์หลัก นั่นคือ โมเดลการคาดการณ์ทั่วไปที่มีรายละเอียดมากที่สุด อย่างไรก็ตาม วันนี้มีแบบจำลองการคาดการณ์อนุกรมเวลาจำนวนมากอยู่แล้ว และสำหรับการคาดการณ์ เช่น โมเดล SVM (เครื่องสนับสนุนเวกเตอร์) โมเดล GA (อัลกอริทึมทางพันธุกรรม) และอื่นๆ อีกมากมายได้เริ่มถูกนำมาใช้แล้ว
การจำแนกประเภททั่วไป
ดังนั้นเราจึงได้ดังต่อไปนี้ การจำแนกแบบจำลองและวิธีการพยากรณ์.

- Tikhonov E.E. การพยากรณ์สภาวะตลาด Nevinnomyssk, 2549 221 น.
- อาร์มสตรอง เจ.เอส. การพยากรณ์การตลาด // วิธีการเชิงปริมาณในการทำการตลาด ลอนดอน: International Thompson Business Press, 1999, หน้า 92–119
- Jingfei Yang M. Sc. การพยากรณ์โหลดไฟฟ้าระยะสั้นของระบบไฟฟ้า: วิทยานิพนธ์ระดับปริญญาเอก เยอรมนี, ดาร์มสตัดท์, Elektrotechnik และ Informationstechnik der Technischen Universitat, 2006. 139 หน้า
ยูพีดี 15/11/2559.
ท่านสุภาพบุรุษ มันบ้าไปแล้ว! เมื่อเร็ว ๆ นี้ ฉันได้รับบทความสำหรับรุ่น VAK พร้อมลิงก์ไปยังรายการนี้เพื่อตรวจสอบ ฉันดึงความสนใจของคุณไปที่ความจริงที่ว่าทั้งในประกาศนียบัตรหรือในบทความและยิ่งกว่านั้นในวิทยานิพนธ์ ลิงค์เข้าบล็อกไม่ได้! หากคุณต้องการลิงค์ให้ใช้ลิงค์นี้: ชูชูวา ไอ.เอ. แบบจำลองการคาดการณ์ของอนุกรมเวลาในการเลือกความคล้ายคลึงสูงสุด วิทยานิพนธ์…แคน เหล่านั้น. วิทยาศาสตร์ / มหาวิทยาลัยเทคนิคแห่งรัฐมอสโก เน.อี. บาวแมน. มอสโก, 2555.
ภาคผนวก 1 วิธีการวิเคราะห์ทางสถิติและการพยากรณ์ในธุรกิจ
4. เครื่องมือพยากรณ์ทางคณิตศาสตร์
วิธีการและแบบจำลองทางคณิตศาสตร์ที่ใช้ในปัญหาของการวิเคราะห์สุ่มและการพยากรณ์ในธุรกิจสามารถเกี่ยวข้องกับสาขาต่างๆ ของคณิตศาสตร์: การวิเคราะห์การถดถอย การวิเคราะห์อนุกรมเวลา การก่อตัวและการประเมินความคิดเห็นของผู้เชี่ยวชาญ แบบจำลองการจำลอง ระบบสมการพร้อมกัน การวิเคราะห์การเลือกปฏิบัติ แบบจำลอง probit เครื่องมือของฟังก์ชันการตัดสินใจเชิงตรรกะ การวิเคราะห์ความแปรปรวนหรือความแปรปรวนร่วม การวิเคราะห์ความสัมพันธ์ของอันดับและตารางฉุกเฉิน ฯลฯ อย่างไรก็ตาม สิ่งเหล่านี้ล้วนรวมกันเป็นหนึ่งโดยข้อเท็จจริงที่ว่าพวกเขาเป็นตัวแทนของแนวทางต่างๆ ในการแก้ปัญหาศูนย์กลางของการวิเคราะห์ทางสถิติหลายตัวแปรและ เศรษฐมิติ - ปัญหาการศึกษาทางสถิติของการพึ่งพาอาศัยกันซึ่งเป็นเพียง ปัญหาพื้นฐานของการวิเคราะห์และการพยากรณ์ทางสถิติในธุรกิจ (สูตรทั่วไปได้รับในวรรค 2)
ในวรรค 1 สังเกตแล้วว่าในหมู่ p+k+l+mส่วนประกอบของคุณลักษณะหลายมิติที่วิเคราะห์แล้วสามารถเป็นได้ทั้งตัวแปรเชิงปริมาณและตัวแปรลำดับและตัวแปรระบุ วิธีการที่กล่าวข้างต้นในการแก้ปัญหาศูนย์กลางของการวิเคราะห์ทางสถิติหลายตัวแปรถูกสร้างขึ้นโดยคำนึงถึงธรรมชาติของตัวแปรที่อยู่ระหว่างการศึกษา ความเชี่ยวชาญเฉพาะทางที่สอดคล้องกันของแนวทางเหล่านี้สะท้อนให้เห็นในตาราง 4. นอกจากนี้ยังมีการอ้างอิงถึงแหล่งวรรณกรรม ซึ่งสามารถหาคำอธิบายที่สมบูรณ์ของแนวทางเหล่านี้ได้
ตารางที่ 4
|
ลักษณะของตัวบ่งชี้ผลลัพธ์ |
ลักษณะของตัวแปรอธิบาย |
ชื่อของส่วนบริการของการวิเคราะห์ทางสถิติหลายตัวแปร |
แหล่งวรรณกรรม |
|
เชิงปริมาณ |
เชิงปริมาณ |
การวิเคราะห์การถดถอยและระบบสมการพร้อมๆ กัน |
|
|
เชิงปริมาณ |
ตัวแปรเชิงปริมาณเพียงอย่างเดียวที่ตีความว่าเป็น "เวลา" |
การวิเคราะห์อนุกรมเวลา |
|
|
เชิงปริมาณ |
Nonquantitative (ตัวแปรลำดับหรือตัวแปรระบุ) |
การวิเคราะห์ความแปรปรวน |
|
|
เชิงปริมาณ |
การวิเคราะห์ความแปรปรวนร่วม ตัวแบบการถดถอยแบบแยกประเภท |
||
|
ไม่ใช่เชิงปริมาณ (ตัวแปรลำดับ) |
Nonquantitative (ตัวแปรลำดับและตัวแปรระบุ) |
การวิเคราะห์ความสัมพันธ์ของอันดับและตารางฉุกเฉิน |
|
|
ไม่ใช่เชิงปริมาณ (ตัวแปรระบุ) |
เชิงปริมาณ |
การวิเคราะห์แบบจำแนก แบบจำลองลอจิทและโพรบิต การวิเคราะห์คลัสเตอร์ อนุกรมวิธาน การแยกสารผสมของการแจกแจง |
|
|
ผสม (ตัวแปรเชิงปริมาณและไม่ใช่เชิงปริมาณ) |
ผสม (ตัวแปรเชิงปริมาณและไม่ใช่เชิงปริมาณ) |
เครื่องมือของฟังก์ชันการตัดสินใจเชิงตรรกะ การทำเหมืองข้อมูล |
อย่างไรก็ตาม การวิเคราะห์เชิงสถิติและการพยากรณ์ในธุรกิจแสดงให้เห็นว่าในสเปกตรัมทั้งหมดของเครื่องมือทางคณิตศาสตร์ ความเป็นผู้นำที่ไม่มีปัญหา (ในแง่ของความชุกและความเกี่ยวข้อง) อยู่ในสามส่วน:
- การวิเคราะห์การถดถอย
-
การวิเคราะห์อนุกรมเวลา
-
กลไกการก่อตัวและการวิเคราะห์ทางสถิติของการประเมินโดยผู้เชี่ยวชาญ
ลองมาดูที่แต่ละส่วนเหล่านี้โดยย่อ
การวิเคราะห์การถดถอย
เช่นเคย เราจะอธิบายการทำงานของวัตถุจริงภายใต้การศึกษา (บริษัท บริษัท กระบวนการผลิต หรือการจำหน่ายผลิตภัณฑ์ ฯลฯ) โดยชุดของตัวแปรและ (ความหมายที่มีความหมายได้อธิบายไว้ในวรรค 2) ให้เราแนะนำคำจำกัดความและแนวคิดจำนวนหนึ่งที่ใช้ในการวิเคราะห์การถดถอย
ผลลัพธ์ (ขึ้นอยู่กับตัวแปรภายนอก)ตัวแปรที่กำหนดลักษณะผลลัพธ์หรือประสิทธิภาพของระบบที่วิเคราะห์เรียกว่าผลลัพธ์ (ขึ้นกับ, ภายนอก) ค่าของมันถูกสร้างขึ้นในระหว่างและภายในการทำงานของระบบนี้ภายใต้อิทธิพลของตัวแปรและปัจจัยอื่น ๆ จำนวนหนึ่งซึ่งบางส่วนสามารถลงทะเบียนได้และจัดการและวางแผนในระดับหนึ่ง (ส่วนนี้มักเรียกว่าตัวแปรอธิบาย ดูด้านล่าง) ในการวิเคราะห์การถดถอย ตัวแปรผลลัพธ์จะทำหน้าที่เป็นฟังก์ชัน ซึ่งค่าที่กำหนด (แม้ว่าจะมีข้อผิดพลาดแบบสุ่ม) โดยค่าของตัวแปรอธิบายที่กล่าวถึงข้างต้นซึ่งทำหน้าที่เป็นอาร์กิวเมนต์ ดังนั้นโดยธรรมชาติแล้ว ตัวแปรที่ได้จึงมักจะสุ่ม (สุ่ม) ในกรณีทั่วไป มักจะวิเคราะห์พฤติกรรมของตัวแปรผลลัพธ์หลายๆ ตัว ![]() .
.
ตัวแปรอธิบาย (ตัวทำนาย, ตัวแปรภายนอก) ![]() . ตัวแปร (หรือสัญญาณ) ที่สามารถลงทะเบียนได้ซึ่งอธิบายเงื่อนไขสำหรับการทำงานของระบบเศรษฐกิจที่แท้จริงภายใต้การศึกษาและในขอบเขตขนาดใหญ่ที่กำหนดกระบวนการสร้างค่าของตัวแปรผลลัพธ์เรียกว่าคำอธิบาย ตามกฎแล้วบางคนยืมตัวไปปฏิบัติตามกฎระเบียบและการจัดการบางส่วนเป็นอย่างน้อย ค่าของตัวแปรอธิบายจำนวนหนึ่งสามารถตั้งค่าได้เสมือนว่า "อยู่นอก" ระบบที่วิเคราะห์ ในกรณีนี้เรียกว่าภายนอก ในการวิเคราะห์การถดถอย พวกเขาเล่นบทบาทของอาร์กิวเมนต์ของฟังก์ชัน ซึ่งถือเป็นตัวบ่งชี้ผลลัพธ์ที่วิเคราะห์ โดยธรรมชาติแล้ว ตัวแปรอธิบายสามารถเป็นได้ทั้งแบบสุ่มและแบบไม่ใช่แบบสุ่ม
. ตัวแปร (หรือสัญญาณ) ที่สามารถลงทะเบียนได้ซึ่งอธิบายเงื่อนไขสำหรับการทำงานของระบบเศรษฐกิจที่แท้จริงภายใต้การศึกษาและในขอบเขตขนาดใหญ่ที่กำหนดกระบวนการสร้างค่าของตัวแปรผลลัพธ์เรียกว่าคำอธิบาย ตามกฎแล้วบางคนยืมตัวไปปฏิบัติตามกฎระเบียบและการจัดการบางส่วนเป็นอย่างน้อย ค่าของตัวแปรอธิบายจำนวนหนึ่งสามารถตั้งค่าได้เสมือนว่า "อยู่นอก" ระบบที่วิเคราะห์ ในกรณีนี้เรียกว่าภายนอก ในการวิเคราะห์การถดถอย พวกเขาเล่นบทบาทของอาร์กิวเมนต์ของฟังก์ชัน ซึ่งถือเป็นตัวบ่งชี้ผลลัพธ์ที่วิเคราะห์ โดยธรรมชาติแล้ว ตัวแปรอธิบายสามารถเป็นได้ทั้งแบบสุ่มและแบบไม่ใช่แบบสุ่ม
เศษถดถอย- สิ่งเหล่านี้เป็นส่วนประกอบสุ่มแฝง (เช่น ซ่อนเร้น ไม่คล้อยตามการวัดโดยตรง) ซึ่งสะท้อนผลกระทบตามลำดับบน ![]() ไม่คำนึงถึงองค์ประกอบของปัจจัย ตลอดจนข้อผิดพลาดแบบสุ่มในการวัดตัวแปรผลลัพธ์ที่วิเคราะห์ โดยทั่วไปแล้ว พวกเขายังสามารถพึ่งพา เช่นในกรณีทั่วไป
ไม่คำนึงถึงองค์ประกอบของปัจจัย ตลอดจนข้อผิดพลาดแบบสุ่มในการวัดตัวแปรผลลัพธ์ที่วิเคราะห์ โดยทั่วไปแล้ว พวกเขายังสามารถพึ่งพา เช่นในกรณีทั่วไป
แผนภาพทั่วไปของการโต้ตอบของตัวแปรในการวิเคราะห์การถดถอยแสดงอยู่ในรูป

รูปภาพ . รูปแบบทั่วไปของการโต้ตอบของตัวแปรในการวิเคราะห์การถดถอย
ฟังก์ชันถดถอย บน. ฟังก์ชันนี้เรียกว่า ฟังก์ชันถดถอยโดย (หรือเพียงแค่ - การถดถอย บน) ถ้ามันอธิบายการเปลี่ยนแปลงในค่าเฉลี่ยตามเงื่อนไขของตัวแปรผลลัพธ์ (สมมติว่าค่าของตัวแปรอธิบายได้รับการแก้ไขที่ระดับ ) ขึ้นอยู่กับการเปลี่ยนแปลงในค่าของตัวแปรอธิบาย ดังนั้น ในทางคณิตศาสตร์ นิยามนี้สามารถเขียนได้เป็น
โดยที่สัญลักษณ์หมายถึงการดำเนินการของค่าเฉลี่ยตามทฤษฎีของค่าต่างๆ (เช่น เป็นการคาดหมายทางคณิตศาสตร์ของตัวแปรสุ่ม และ หรือเพียงแค่เป็นการคาดหมายทางคณิตศาสตร์แบบมีเงื่อนไขของตัวแปรสุ่ม ซึ่งคำนวณภายใต้เงื่อนไขว่าค่าของคำอธิบาย ตัวแปรได้รับการแก้ไขที่ระดับ )
หากเราวิเคราะห์ตัวแปรผลลัพธ์ไปพร้อม ๆ กัน เราควรพิจารณาฟังก์ชันการถดถอยตามลำดับหรือที่เหมือนกัน ค่าเวกเตอร์การทำงาน
 . (11)
. (11)
แล้วตัวแบบถดถอย ![]() สามารถเขียนได้ในรูป
สามารถเขียนได้ในรูป
, (12)
ยิ่งกว่านั้นจากนิยามที่ว่ามาโดยตลอด]
![]() (12’)
(12’)
(เหมือนกันเครื่องหมายเท่ากับ (12') หมายความว่าใช้ได้สำหรับ ใด ๆค่านิยม; เวกเตอร์คอลัมน์ของศูนย์ทางด้านขวามีมิติ )
ปัญหาถดถอยในรูปแบบทั่วไปที่สุดสามารถกำหนดได้ดังนี้:
ตามผลการวัด
ของตัวแปรที่ศึกษาเกี่ยวกับวัตถุ (ระบบ, กระบวนการ) ของประชากรที่วิเคราะห์, สร้างฟังก์ชัน (ค่าเวกเตอร์) ดังกล่าว (11) ที่จะยอมให้วิธีที่ดีที่สุด (ในแง่หนึ่ง) ในการคืนค่าของ ผลลัพธ์ (คาดการณ์) ตัวแปร ![]() โดยให้ค่าของตัวแปรอธิบาย (ภายนอก) .
โดยให้ค่าของตัวแปรอธิบาย (ภายนอก) .
หมายเหตุ 1. ที่พบบ่อยที่สุดคือ เชิงเส้นตัวแบบการถดถอย เช่น ตัวแบบที่ฟังก์ชันการถดถอยมีรูปแบบเชิงเส้น:
หมายเหตุ 2 มีอย่างน้อยสองตัวเลือกในการตีความตัวแปร "พฤติกรรม" "สถานะ" และ "ภายนอก" ที่แนะนำในส่วนที่ 2 ตามลำดับ และภายในกรอบของแบบจำลองการถดถอยที่อธิบายไว้ (12)–(12 ') ในรุ่นแรก ทั้งสามประเภทตัวแปรและอ้างถึงตัวแปรอธิบายและสร้างการถดถอยบน ในอีกรูปแบบหนึ่ง ตัวแปรและถูกตีความว่าเป็น เงื่อนไขการสังเกตแล้วก็ แยกกันสำหรับชุดค่าผสมคงที่แต่ละเงื่อนไขเหล่านี้ แบบจำลองการถดถอยของแบบฟอร์ม (12) จะถูกสร้างขึ้น (ภายในกรอบของแบบจำลองเชิงเส้น (12 '') ซึ่งจะหมายความว่าค่าสัมประสิทธิ์การถดถอยเอง ![]() ขึ้นอยู่กับ และ นั่นคือถูกกำหนดให้เป็นหน้าที่ของ และ )
ขึ้นอยู่กับ และ นั่นคือถูกกำหนดให้เป็นหน้าที่ของ และ )
การวิเคราะห์อนุกรมเวลา
การวิเคราะห์และการคาดการณ์ทางสถิติจะขึ้นอยู่กับข้อมูลทางสถิติเบื้องต้น ประเภทหลักของพวกเขาถูกนำเสนอในวรรค 1 ในเวลาเดียวกันหากกระบวนการของการลงทะเบียนข้อมูลเกิดขึ้นในเวลา และเวลานั้นได้รับการแก้ไขพร้อมกับค่าของลักษณะที่วิเคราะห์แล้วหนึ่งพูดถึงการวิเคราะห์ทางสถิติของ ที่เรียกว่า ข้อมูลแผง. หากเราแก้ไขจำนวนตัวแปรและจำนวนของวัตถุที่ตรวจสอบทางสถิติ ลำดับของค่าจะอยู่ในลำดับเวลา
เรียกว่า อนุกรมเวลาหนึ่งมิติ. อย่างไรก็ตาม หากเราพิจารณาอนุกรมเวลาแบบหนึ่งมิติของแบบฟอร์ม (13) พร้อมกัน นั่นคือ ตรวจสอบรูปแบบใน เชื่อมต่อถึงกันพฤติกรรมของอนุกรมเวลา (13) สำหรับ การกำหนดลักษณะพลวัตของตัวแปร วัดเมื่อ บางคน(-ม.) วัตถุแล้วพวกเขาก็พูดถึง การวิเคราะห์ทางสถิติ อนุกรมเวลาหลายตัวแปร. โดยพื้นฐานแล้ว งานทั้งหมดที่เกี่ยวข้องกับการวิเคราะห์พลวัตทางเศรษฐกิจและการพยากรณ์เกี่ยวข้องกับการใช้อนุกรมเวลาของตัวบ่งชี้บางตัวเป็นฐานทางสถิติ
ตามกฎแล้วในงานพยากรณ์ธุรกิจเท่านั้น ไม่ต่อเนื่อง (ตามเวลาสังเกต) อนุกรมเวลาหนึ่งมิติสำหรับ ช่วงเวลาการสังเกตที่เว้นระยะเท่ากันคือช่วงเวลาที่กำหนด (นาที ชั่วโมง วัน สัปดาห์ เดือน ไตรมาส ปี ฯลฯ) อยู่ที่ไหน ในกรณีเหล่านี้ เราจะสะดวกกว่าในการแสดงอนุกรมเวลาภายใต้การศึกษาในรูปแบบ
ค่าของตัวบ่งชี้ที่วิเคราะห์อยู่ที่ไหนซึ่งลงทะเบียนในขั้นตอนที่ th
เมื่อพูดถึงการใช้อุปกรณ์ของการวิเคราะห์อนุกรมเวลาในปัญหาการพยากรณ์ เราหมายถึง สั้นๆ- และระยะกลาง พยากรณ์,เพราะว่าการก่อสร้าง ระยะยาวการคาดการณ์หมายถึงการใช้วิธีการขององค์กรและการวิเคราะห์ทางสถิติบังคับ การประเมินโดยผู้เชี่ยวชาญพิเศษ.
กำเนิดของการสังเกตที่สร้างอนุกรมเวลา. เรากำลังพูดถึงโครงสร้างและการจำแนกปัจจัยหลักภายใต้อิทธิพลของค่าขององค์ประกอบของอนุกรมเวลา ขอแนะนำให้แยกแยะปัจจัยดังกล่าว 4 ประเภทต่อไปนี้
(แต่) ระยะยาวสร้างแนวโน้มทั่วไป (ในระยะยาว) ในการเปลี่ยนแปลงลักษณะที่วิเคราะห์ โดยปกติแนวโน้มนี้จะอธิบายโดยใช้ฟังก์ชันที่ไม่สุ่มอย่างใดอย่างหนึ่ง ฉ tr (เสื้อ)มักจะซ้ำซากจำเจ ฟังก์ชันนี้เรียกว่า ฟังก์ชั่นแนวโน้มหรือง่ายๆ แนวโน้ม.
(ข) ตามฤดูกาลซึ่งก่อให้เกิดความผันผวนของลักษณะที่วิเคราะห์ซ้ำเป็นระยะในช่วงเวลาหนึ่งของปี ให้เราตกลงที่จะแสดงผลลัพธ์ของการกระทำของปัจจัยตามฤดูกาลโดยใช้ฟังก์ชันที่ไม่ใช่การสุ่ม เนื่องจากฟังก์ชันนี้ควรเป็น วารสาร(ด้วยช่วงเวลาที่เป็นทวีคูณของฤดูกาลเช่นไตรมาส) ฮาร์โมนิก (ฟังก์ชันตรีโกณมิติ) มีส่วนร่วมในนิพจน์การวิเคราะห์ซึ่งโดยปกติแล้วจะกำหนดโดยเนื้อหาของปัญหา
(ใน) วัฏจักร (ฉวยโอกาส) ที่ก่อให้เกิดการเปลี่ยนแปลงในลักษณะที่วิเคราะห์เนื่องจากการกระทำของวัฏจักรระยะยาวของธรรมชาติทางเศรษฐกิจ ประชากรศาสตร์ หรือฟิสิกส์ดาราศาสตร์ (คลื่น Kondratiev, "หลุม" ทางประชากรศาสตร์, วัฏจักรของกิจกรรมแสงอาทิตย์ ฯลฯ ) ผลของการกระทำของปัจจัยที่เป็นวัฏจักรจะแสดงด้วยฟังก์ชันที่ไม่สุ่ม
(ช) สุ่ม(ผิดปกติ) ไม่คล้อยตามการบัญชีและการลงทะเบียน ผลกระทบต่อการก่อตัวของค่าของอนุกรมเวลาเพียงแค่กำหนด ธรรมชาติสุ่มองค์ประกอบต่างๆ และด้วยเหตุนี้จึงจำเป็นต้องตีความจากการสังเกตของตัวแปรสุ่มตามลำดับ เราจะแสดงผลลัพธ์ของผลกระทบของปัจจัยสุ่มด้วยความช่วยเหลือของตัวแปรสุ่ม ("เศษ", "ข้อผิดพลาด") แน่นอนว่าไม่จำเป็นเลยที่ปัจจัยจะมีส่วนร่วมในกระบวนการสร้างค่าของอนุกรมเวลาใดๆ พร้อมกัน ทั้งหมดสี่ประเภท ในบางกรณี ค่าของอนุกรมเวลาสามารถเกิดขึ้นได้ภายใต้อิทธิพลของปัจจัย (A), (B) และ (D) ในบางกรณี - ภายใต้อิทธิพลของปัจจัย (A), (C) และ (D ) และสุดท้ายภายใต้อิทธิพลของปัจจัยเท่านั้น ปัจจัยสุ่ม (D) อย่างไรก็ตามในทุกกรณี การมีส่วนร่วมที่ขาดไม่ได้ของการสุ่ม (วิวัฒนาการ) ปัจจัย (D).นอกจากนี้ยังเป็นที่ยอมรับโดยทั่วไป (ตามสมมติฐาน) โครงสร้างเสริม โครงการอิทธิพลของปัจจัย (A), (B), (C) และ (D) ต่อการก่อตัวของค่านิยมซึ่งหมายถึงความถูกต้องของการแสดงค่าของสมาชิกของอนุกรมเวลาในรูปแบบของการสลายตัว:
ข้อสรุปว่าปัจจัยประเภทนี้เกี่ยวข้องหรือไม่ในการก่อตัวของค่านิยมทั้งจากการวิเคราะห์สาระสำคัญของเนื้อหาของงาน (เช่น เป็น ผู้เชี่ยวชาญด้านธรรมชาติ) และตอนพิเศษ การวิเคราะห์ทางสถิติของอนุกรมเวลาที่ศึกษา.
ภายในกรอบแนวคิดและสัญกรณ์ที่แนะนำ ปัญหาการวิเคราะห์ทางสถิติอนุกรมเวลาโดยทั่วไปสามารถกำหนดได้ดังนี้:
จากผลการวัดของตัวแปรภายใต้การศึกษาสำหรับช่วงเวลาของช่วงเวลาฐาน ให้สร้างการประมาณการที่ดีที่สุด (ในแง่หนึ่ง) สำหรับเงื่อนไขการขยาย (14)
การแก้ปัญหานี้ใช้เพื่อสร้างค่าการทำนายสำหรับเวลาที่อยู่ข้างหน้าโดยใช้สูตร (14) และเมื่อแทนที่การประมาณการที่ได้รับของส่วนประกอบทางด้านขวามือของการสลายตัวเข้าไป
กลไกการก่อตัวและการวิเคราะห์ทางสถิติของการประเมินของผู้เชี่ยวชาญ
โดยปกติองค์กรประเภทหลักต่อไปนี้ของงานของกลุ่มผู้เชี่ยวชาญ () มีความโดดเด่น:
· วิทยาลัย: “วิธีการของค่าคอมมิชชั่น” (ในรูปแบบของการอภิปรายแบบเปิดเกี่ยวกับปัญหาภายใต้การสนทนา); "วิธีศาล" (ในรูปแบบของการเผชิญหน้าระหว่าง "การป้องกัน" และ "ค่าใช้จ่าย" สำหรับแต่ละตัวเลือกสำหรับวิธีแก้ปัญหาที่กล่าวถึง); "ระดมความคิด" ฯลฯ ;
· วิทยาลัยบางส่วน:การวิเคราะห์สถานการณ์ของประเภท "what-if" วิธี "Delphi" - การอภิปรายหลายรอบเกี่ยวกับปัญหาการลงคะแนนลับของผู้เชี่ยวชาญหรือกรอกแบบสอบถามที่ไม่ระบุชื่อพิเศษในตอนท้ายของแต่ละรอบและงานของกลุ่มวิเคราะห์อิสระ ในระหว่างรอบ ฯลฯ .;
· เป็นรายบุคคล-อิสระ:สมาชิกของกลุ่มผู้เชี่ยวชาญแต่ละคนสร้างและแสดงความคิดเห็นของเขา (โดยไม่คำนึงถึงตำแหน่งของผู้เข้าร่วมคนอื่น ๆ ) ในรูปแบบของการจัดอันดับวิธีแก้ปัญหาที่กล่าวถึง (หรือวัตถุ) การเปรียบเทียบคู่ของพวกเขาหรือมอบหมายให้แต่ละคนมีการไล่ระดับที่อธิบายไว้ก่อนหน้านี้ (ดูรูปแบบการนำเสนอข้อมูลสถิติเบื้องต้นในรูปแบบของตารางความถี่หรือตารางฉุกเฉิน ระหว่างความคิดเห็นของผู้เชี่ยวชาญที่ -th และ -th วัดจากค่า โดยที่ค่าสัมประสิทธิ์สหสัมพันธ์อันดับสเปียร์แมนอยู่ที่ (ดู Ch. 11]) จากนั้นเราสามารถแก้ปัญหา "การจัดกลุ่ม" ของผู้เชี่ยวชาญโดยตีความแต่ละกลุ่มที่พบในลักษณะนี้ในฐานะกลุ่มผู้เชี่ยวชาญที่มีใจเดียวกัน
(ii) การวิเคราะห์ความเห็นร่วมกันของกลุ่มผู้เชี่ยวชาญด้วยความเห็นของผู้เชี่ยวชาญทั้งกลุ่ม นักสถิติจึงพยายามประเมินระดับความสอดคล้องของการประเมินโดยผู้เชี่ยวชาญเหล่านี้ทั้งหมด รวมถึงการทดสอบทางสถิติสมมติฐานว่าไม่มีความสอดคล้องกันโดยสมบูรณ์ (และแน่นอนว่าเราควรชี้แจงการกำหนดของ ปัญหาที่ผู้เชี่ยวชาญเสนอหรือเปลี่ยนกลุ่มผู้เชี่ยวชาญองค์ประกอบ) ปัญหานี้แก้ไขได้ด้วยการวิเคราะห์ทางสถิติหลายตัวแปร การเลือกวิธีการเฉพาะขึ้นอยู่กับรูปแบบของข้อมูลสถิติเบื้องต้น ตัวอย่างเช่น หากความคิดเห็นของผู้เชี่ยวชาญแสดงโดยการจัดอันดับ ก็สามารถพิจารณาเป็นตัวชี้วัดความสอดคล้องกันได้ สัมประสิทธิ์ของวัตถุ) เช่น ด้วยข้อมูลสถิติเริ่มต้นของแบบฟอร์มถูกกำหนดให้เป็นวิธีแก้ปัญหาการปรับให้เหมาะสมของแบบฟอร์ม j- ผู้เชี่ยวชาญคนที่อยู่ไกลจากความคิดเห็นของกลุ่มที่เป็นปึกแผ่น ระดับความสามารถสัมพัทธ์ของเขาจะต่ำกว่าที่ประมาณการไว้ โปรดทราบว่าหากจากการศึกษาโครงสร้างยอดรวมของความคิดเห็นของผู้เชี่ยวชาญแล้ว นักสถิติสรุปได้ว่า ผู้เชี่ยวชาญหลายกลุ่มย่อยด้วยความคิดเห็นที่เป็นเนื้อเดียวกันภายในแต่ละกลุ่มย่อยและมีความแตกต่างอย่างมีนัยสำคัญในความคิดเห็นในกลุ่มย่อยใด ๆ คู่ใด ๆ จากนั้นงานของความคิดเห็นกลุ่มเดียวและการประเมินความสามารถสัมพัทธ์ของผู้เชี่ยวชาญจะได้รับการแก้ไขแยกกันสำหรับแต่ละกลุ่มย่อยที่ระบุ
ในทางกลับกัน ปัจจัยสุ่มสามารถมีลักษณะเป็นสองเท่า: กะทันหัน(“ความผิดปกติ”) นำไปสู่การเปลี่ยนแปลงโครงสร้างอย่างฉับพลันในกลไกของการก่อตัวของค่า x(ท)(ซึ่งแสดงออกมา เช่น ในการเปลี่ยนแปลงเป็นพักๆ อย่างรุนแรงในลักษณะโครงสร้างพื้นฐานของการทำงาน ฉ tr(t), เจ(ท)และ y(ท)วิเคราะห์อนุกรมเวลาแบบสุ่ม) และ สารตกค้างจากวิวัฒนาการทำให้ค่าเบี่ยงเบนแบบสุ่มค่อนข้างน้อย x(ท)จากผู้ที่ควรจะได้รับ ภายใต้อิทธิพลของปัจจัยต่างๆ (A), (B) และ (C)อย่างไรก็ตาม ในส่วนนี้ แผนการสร้างอนุกรมเวลาจะได้รับการพิจารณา ซึ่งรวมถึงการดำเนินการ วิวัฒนาการเท่านั้น ปัจจัยสุ่มที่เหลือ
| ก่อนหน้า |
นอกจากนี้เรายังแนะนำ
 แหล่งจ่ายไฟสลับ: การซ่อมแซมและการปรับแต่ง
แหล่งจ่ายไฟสลับ: การซ่อมแซมและการปรับแต่ง
 การควบคุมระยะไกลของแสง
การควบคุมระยะไกลของแสง
 เรียนว่ายน้ำสำหรับเด็กก่อนวัยเรียน
เรียนว่ายน้ำสำหรับเด็กก่อนวัยเรียน
 หมายเหตุสำหรับเจ้านาย - การเตือนภัยในครัวเรือนที่บ้าน
หมายเหตุสำหรับเจ้านาย - การเตือนภัยในครัวเรือนที่บ้าน
 ใบพัดนาฬิกาบน Atmega8
ใบพัดนาฬิกาบน Atmega8
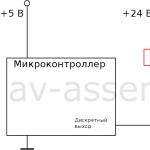 ตัวอย่างการใช้งานอุปกรณ์และรีเลย์ วิธีการเลือกและเชื่อมต่อรีเลย์อย่างถูกต้อง ไมโครคอนโทรลเลอร์และรีเลย์ วงจรสวิตชิ่งอย่างง่าย
ตัวอย่างการใช้งานอุปกรณ์และรีเลย์ วิธีการเลือกและเชื่อมต่อรีเลย์อย่างถูกต้อง ไมโครคอนโทรลเลอร์และรีเลย์ วงจรสวิตชิ่งอย่างง่าย