Mesures en recherche marketing. Types d'échelles utilisées dans la différentielle sémantique Exemple d'échelle différentielle sémantique
La présence de jugements contradictoires dans les réponses sur l'échelle B conduit à considérer l'échelle comme inacceptable.
Cette approche pour augmenter la fiabilité d’une balance est très complexe. Par conséquent, cela ne peut être recommandé que lors du développement de tests critiques ou de techniques destinées à une utilisation de masse ou à des études par panel.
Il est possible de tester une méthode sur plusieurs répondants. Si la méthode est fiable, alors les différents répondants donneront des informations cohérentes, mais si leurs résultats sont peu cohérents, alors soit les mesures ne sont pas fiables, soit les résultats des répondants individuels ne peuvent pas être considérés comme équivalents. Dans ce dernier cas, il est nécessaire de déterminer si un groupe de résultats peut être considéré comme plus fiable. La solution à ce problème est d'autant plus importante si l'on suppose qu'il est également permis d'obtenir des informations par n'importe laquelle des méthodes considérées.
L’utilisation de méthodes parallèles pour mesurer la même propriété se heurte à un certain nombre de difficultés.
Premièrement, il n’est pas clair dans quelle mesure les deux méthodes mesurent la même qualité de l’objet et, en règle générale, il n’existe aucun critère formel pour tester une telle hypothèse. Par conséquent, il est nécessaire de recourir à une justification substantielle (logique-théorique) d'une méthode particulière.
Deuxièmement, si des procédures parallèles sont trouvées pour mesurer une propriété commune (les données ne diffèrent pas de manière significative), la question demeure quant à la justification théorique de l'utilisation de ces procédures.
Il faut admettre que le principe même du recours à des procédures parallèles s'avère être non pas un principe formel, mais plutôt un principe de fond dont l'application est très difficile à justifier théoriquement.
L'une des approches les plus répandues pour établir la validité consiste à faire appel à ce qu'on appelle des juges, des experts. Les chercheurs demandent à un groupe spécifique de personnes d’agir en tant qu’individus compétents. On leur propose un ensemble de caractéristiques destinées à mesurer l'objet étudié, et il leur est demandé d'évaluer l'exactitude de l'attribution de chacune des caractéristiques à cet objet. Le traitement conjoint des avis des juges permettra d'attribuer des poids aux caractéristiques ou, ce qui revient au même, des notes d'échelle dans la mesure de l'objet étudié. Un ensemble de caractéristiques peut être une liste de jugements individuels, de caractéristiques d'un objet, etc.
Les procédures de jugement sont variées. Ils peuvent être fondés sur des méthodes de comparaisons appariées, de classement, d'intervalles séquentiels, etc.
La question de savoir qui doit être considéré comme juge est assez controversée. Les juges sélectionnés comme représentants de la population étudiée doivent, d’une manière ou d’une autre, représenter son micromodèle : selon les appréciations des juges, le chercheur détermine dans quelle mesure certains points de la procédure d’enquête seront interprétés par les répondants.
Cependant, lors de la sélection des juges, une question difficile se pose : quelle est l'influence des propres attitudes des juges sur leurs appréciations, car ces attitudes peuvent différer sensiblement des attitudes des sujets par rapport au même objet.
D'une manière générale, la solution au problème consiste à : a) analyser soigneusement la composition des juges du point de vue de l'adéquation de leur expérience de vie et des signes de leur statut social aux indicateurs correspondants de la population interrogée ; b) identifier l'effet des écarts individuels dans les notes des juges par rapport à la distribution globale des notes. Enfin, il est nécessaire d’évaluer non seulement la qualité, mais également la taille de l’échantillon de juges.
D'une part, ce nombre est déterminé par la cohérence : si la cohérence des avis des juges est suffisamment élevée et, par conséquent, l'erreur de mesure est faible, le nombre de juges peut être faible. Il est nécessaire de définir la valeur de l'erreur tolérée et, sur cette base, de calculer la taille d'échantillon requise.
Si une incertitude totale de l'objet est détectée, c'est-à-dire dans le cas où les avis des juges sont répartis uniformément dans toutes les catégories d'évaluation, aucune augmentation de la taille de l'échantillon de juges ne sauvera la situation et ne fera pas sortir l'objet du état d’incertitude.
Si l'objet est suffisamment incertain, un grand nombre de gradations ne fera qu'introduire une interférence supplémentaire dans le travail des juges et ne fournira pas d'informations plus précises. Il est nécessaire d'identifier la stabilité des opinions des juges à l'aide de tests répétés et, en conséquence, de réduire le nombre de gradations.
Le choix d'une méthode, d'une méthode ou d'une technique particulière pour vérifier la validité dépend de nombreuses circonstances.
Tout d'abord, il convient d'établir clairement si des écarts significatifs par rapport au programme de mesure prévu sont possibles. Si le programme de recherche fixe des limites strictes, non pas une, mais plusieurs méthodes doivent être utilisées pour vérifier la validité des données.
Deuxièmement, il faut garder à l’esprit que les niveaux de robustesse et de validité des données sont étroitement liés. Les informations instables, du fait de leur manque de fiabilité selon ce critère, ne nécessitent pas une vérification de validité trop stricte. Une robustesse suffisante doit être assurée, puis des mesures appropriées doivent être prises pour clarifier les limites de l'interprétation des données (c'est-à-dire identifier le niveau de validité).
De nombreuses expériences visant à identifier le niveau de fiabilité permettent de conclure que dans le processus de développement des instruments de mesure, en termes de fiabilité, la séquence suivante des principales étapes de travail est conseillée :
a) Contrôle préliminaire de la validité des méthodes de mesure des données primaires au stade du test de la méthodologie. Il est ici vérifié dans quelle mesure les informations répondent essentiellement à leur objectif prévu et quelles sont les limites de l'interprétation ultérieure des données. À cette fin, de petits échantillons de 10 à 20 observations suffisent, suivis d’ajustements de la structure de la méthodologie.
b) La deuxième étape consiste à piloter la méthodologie et à vérifier minutieusement la stabilité des données initiales, notamment les indicateurs et échelles sélectionnés. À ce stade, il faut un échantillon qui représente un micromodèle de la population réelle des répondants.
c) Au cours d'une même voltige générale, toutes les opérations nécessaires liées à la vérification du niveau de validité sont effectuées. Les résultats de l'analyse des données pilotes conduisent à l'amélioration de la méthodologie, au raffinement de tous ses détails et, finalement, à l'obtention de la version finale de la méthodologie pour l'étude principale.
d) Au début de l'étude principale, il convient de vérifier la stabilité de la méthode utilisée afin de calculer des indicateurs précis de sa stabilité. La clarification ultérieure des limites de validité passe par l'ensemble de l'analyse des résultats de l'étude elle-même.
Quelle que soit la méthode d’évaluation de la fiabilité utilisée, le chercheur dispose de quatre étapes séquentielles pour améliorer la fiabilité des résultats de mesure.
Premièrement, lorsque la fiabilité des mesures est extrêmement faible, certaines questions sont simplement supprimées du questionnaire, en particulier lorsque le degré de fiabilité peut être déterminé au cours du processus d’élaboration du questionnaire.
Deuxièmement, le chercheur peut « réduire » les échelles et utiliser moins de gradations. Disons que l'échelle de Likert dans ce cas ne peut comprendre que les gradations suivantes : « d'accord », « pas d'accord », « je n'ai pas d'opinion ». Cela se fait généralement lorsque la première étape est terminée et lorsque l'examen a déjà été effectué.
Troisièmement, comme alternative à la deuxième étape ou comme approche menée après la deuxième étape, l'évaluation de la fiabilité est réalisée au cas par cas. Disons qu'une comparaison directe est faite des réponses des répondants lors de leurs tests initiaux et retestés ou avec une réponse équivalente. Les réponses des répondants peu fiables ne sont tout simplement pas prises en compte dans l’analyse finale. Évidemment, si vous utilisez cette approche sans évaluation objective de la fiabilité des répondants, alors en rejetant les réponses « indésirables », les résultats de la recherche peuvent être ajustés à ceux souhaités.
Enfin, après avoir utilisé les trois premières étapes, le niveau de fiabilité des mesures peut être évalué. Typiquement, la fiabilité des mesures est caractérisée par un coefficient variant de zéro à un, où l'on caractérise la fiabilité maximale.
On considère généralement que le niveau minimum acceptable de fiabilité est caractérisé par des nombres compris entre 0,65 et 0,70, surtout si les mesures ont été effectuées pour la première fois.
Il est évident qu'au cours du processus d'études marketing diverses et nombreuses menées par différentes entreprises, il y a eu une adaptation cohérente des échelles de mesure et des méthodes de leur mise en œuvre aux buts et objectifs d'études marketing spécifiques. Cela facilite la résolution des problèmes abordés dans cette section et le rend plutôt nécessaire lors de la réalisation d'une étude marketing originale.
La validité des mesures caractérise des aspects complètement différents de la fiabilité des mesures. Une mesure peut être fiable mais non valide. Cette dernière caractérise la précision des mesures par rapport à ce qui existe dans la réalité. Par exemple, on a interrogé un répondant sur son revenu annuel, qui est inférieur à 25 000 $. Réticent à donner le chiffre exact à l’intervieweur, le répondant a déclaré un revenu « supérieur à 100 000 $ ». Lors d'un nouveau test, il a de nouveau nommé ce chiffre, démontrant un haut niveau de fiabilité des mesures. Le mensonge n’est pas la seule raison du faible niveau de fiabilité des mesures. On peut aussi parler de mauvaise mémoire, de mauvaise connaissance de la réalité par le répondant, etc.
Considérons un autre exemple qui caractérise la différence entre fiabilité et validité des mesures. Même une montre inexacte affichera l’heure à une heure deux fois par jour, démontrant une grande fiabilité. Cependant, ils peuvent être très imprécis, c'est-à-dire L’affichage de l’heure ne sera pas fiable.
La principale direction pour vérifier la fiabilité des mesures est d'obtenir des informations provenant de diverses sources. Cela peut se faire de différentes façons. Ici, tout d'abord, il convient de noter ce qui suit.
Nous devons nous efforcer de formuler les questions de manière à ce que leur formulation contribue à obtenir des réponses fiables. D'autres questions liées les unes aux autres peuvent être incluses dans le questionnaire.
Par exemple, le questionnaire contient une question sur la mesure dans laquelle le répondant aime un certain produit alimentaire d'une certaine marque. Il est ensuite demandé quelle quantité de ce produit a été achetée par le répondant au cours du mois dernier. Cette question vise à vérifier la fiabilité de la réponse à la première question.
Souvent, deux méthodes ou sources d'informations différentes sont utilisées pour évaluer la fiabilité des mesures. Par exemple, après avoir rempli des questionnaires écrits, un certain nombre de répondants de l'échantillon initial se voient en outre poser les mêmes questions par téléphone. Sur la base de la similitude des réponses, le degré de leur fiabilité est jugé.
Parfois, sur la base des mêmes exigences, deux échantillons de répondants sont constitués et leurs réponses sont comparées pour évaluer le degré de fiabilité.
Questions à vérifier :
Qu’est-ce que la mesure ?
En quoi la mesure objective diffère-t-elle de la mesure subjective ?
Décrire les quatre caractéristiques de l'échelle.
Définir les quatre types d’échelles et indiquer les types d’informations contenues dans chacune.
Quels sont les arguments pour et contre l’utilisation d’une gradation neutre dans une échelle symétrique ?
Qu'est-ce qu'une échelle de Likert modifiée et quel est le lien entre l'échelle de style de vie et l'échelle différentielle sémantique ?
Qu’est-ce que « l’effet de halo » et comment un chercheur doit-il le contrôler ?
Quels éléments déterminent le contenu de la notion de « fiabilité des mesures » ?
Quels inconvénients peut présenter l’échelle de mesure utilisée ?
Quelles méthodes d'évaluation de la stabilité des mesures connaissez-vous ?
Quelles approches connaissez-vous pour évaluer le niveau de validité des mesures ?
En quoi la fiabilité des mesures diffère-t-elle de la validité des mesures ?
Quand un chercheur doit-il évaluer la fiabilité et la validité d’une mesure ?
Supposons que vous soyez engagé dans une étude de marché et que le propriétaire d'une épicerie privée vous a contacté pour vous demander de créer une image positive de ce magasin. Concevoir une échelle différentielle sémantique pour mesurer les dimensions pertinentes de l'image d'un magasin donné. Lors de l'exécution de ce travail, vous devez procéder comme suit :
UN. Organisez une séance de brainstorming pour identifier un ensemble d’indicateurs mesurables.
b. Trouvez les définitions bipolaires correspondantes.
V. Déterminez le nombre de gradations sur l’échelle.
d. Choisissez une méthode pour contrôler « l’effet de halo ».
Concevoir une échelle de mesure (justifier le choix de l'échelle, le nombre de gradations, la présence ou l'absence d'un point neutre ou d'une gradation ; demandez-vous si vous mesurez ce que vous aviez prévu de mesurer) pour les tâches suivantes :
UN. Un fabricant de jouets pour enfants veut savoir comment les enfants d'âge préscolaire réagissent au jeu vidéo « Chante avec nous », dans lequel l'enfant doit chanter avec les personnages du film d'animation.
b. Un fabricant de produits laitiers teste cinq nouvelles saveurs de yaourt et souhaite savoir comment les consommateurs évaluent les saveurs en termes de douceur, d'agrément et de richesse.
Liste littérature
Burns Alvin C., Bush Ronald F. Recherche marketing. New Jersey, Prentice Hall, 1995.
Evlanov L.G. Théorie et pratique de la prise de décision. M., Économie, 1984.
Eliseeva I.I., Yuzbashev M.M. Théorie générale de la statistique.M., Finance et Statistique, 1996.
Cahier d'exercices d'un sociologue. M., Nauka, 1977.
Pour préparer ce travail, des matériaux ont été utilisés du site http://www.marketing.spb.ru/
Page actuelle : 4 (le livre compte 9 pages au total) [passage de lecture disponible : 7 pages]
Thème 4. MÉTHODE D'ÉCHANTILLONNAGE POUR LA COLLECTE D'INFORMATIONS, LA DÉTERMINATION DU VOLUME ET LA PROCÉDURE D'ÉCHANTILLONNAGE
1. Situation problématique« Recherche de nouvelles perspectives commerciales »
L'entrepreneur I. Ivanov envisage la possibilité d'organiser une agence de publicité à cycle complet dans la ville de N, offrant aux clients la quasi-totalité de la gamme de services publicitaires. Selon lui, le service sera demandé car le marché des biens de consommation dans la ville de N est prometteur (les fabricants biélorusses le développent actuellement activement), en d'autres termes, la capacité du marché est assez élevée. Compte tenu de la nouveauté de cette activité, Ivanov souhaite analyser la situation du marché et tirer des conclusions sur l'attractivité d'une telle entreprise.
Pour résoudre ce problème, il a été décidé de mener une étude de la situation concurrentielle sur le marché, ainsi que d'identifier les segments de marché qui devraient être ciblés par l'agence de publicité.
Lors de l'étude de la situation concurrentielle, les sous-tâches suivantes peuvent être identifiées : rechercher les offres des agences concurrentes, déterminer le volume de l'offre de services publicitaires sur le marché de la ville N, décrire les services publicitaires fournis, segmenter par niches tarifaires, identifier le mécanisme de interaction avec les grandes entreprises clientes, évaluation des perspectives de clients s'éloignant des concurrents les plus proches, évaluation par les consommateurs de la qualité du service fourni par leurs concurrents les plus proches.
L’étude du segment des grandes entreprises clientes devrait être réalisée dans les domaines suivants : identification des besoins des clients en services d’agence, évaluation du volume de la demande de services, identification des orientations tarifaires des clients, étude des mécanismes d’une éventuelle coopération.
Questions et tâches
1. Quelles sources d’informations secondaires peuvent être utilisées pour résoudre les problèmes ?
2. Quelles méthodes d’études marketing peuvent être utilisées dans ce cas ?
3. Qui constitue la population aux fins de cette étude ?
2. Situation problématique « Nouveau produit sur le marché »
Une petite entreprise de confiserie produisant des gâteaux a développé un nouveau produit - un gâteau diététique à faible teneur en calories, qu'elle envisage de fournir au marché de la ville de N et de la région. La direction de l'entreprise envisage d'organiser le travail dans le segment de vente au détail du marché urbain. De plus, la direction de l'entreprise dispose d'informations sur les concurrents directs. Il est également prévu de collecter des informations sur les fabricants de produits de substitution. Un audit marketing a montré que l'entreprise n'a pas d'idée du public cible et n'a pas non plus de stratégie de positionnement claire. Pour clarifier ces circonstances, il est prévu de réaliser une étude de marché dont les principaux objectifs sont :
– identifier les consommateurs potentiels de gâteaux diététiques ;
– identifier les caractéristiques comportementales des consommateurs cibles (fréquence de consommation, orientations en matière de prix, problèmes de santé existants, personnes enclines à consommer de nouveaux produits ; personnes surveillant leur poids) ;
– évaluation de la capacité potentielle du marché ;
– identification des concurrents directs et des concurrents dans la production de biens de substitution ;
– segmentation des consommateurs de gâteaux diététiques ;
– le positionnement des produits sur des segments de marché sélectionnés ;
– étude des canaux de distribution possibles.
Questions et tâches
1. Déterminer les méthodes de recherche et les sources d'informations secondaires.
2. Justifier les méthodes d'échantillonnage.
3. Qui constitue la population aux fins de l'étude ?
3. Situation problématique« Tester une nouvelle étiquette »
OJSC Pivo prévoit d'introduire du kvas avec un nouveau label sur le marché régional. Plusieurs agences de publicité de Moscou ont présenté des options d'étiquetage développées. La direction de l'entreprise a donc décidé de mener des études de marché afin d'identifier la meilleure option d'étiquetage du point de vue des représentants du public cible.
Le service marketing s'est vu confier les tâches suivantes :
– identifier les préférences des consommateurs concernant le produit « kvass » (volume, forme et couleur de la bouteille, etc.) ;
– évaluer la perception des consommateurs à l'égard de la nouvelle option d'étiquetage ;
– évaluer l’opinion des consommateurs cibles sur les informations contenues sur l’étiquette.
La méthode d'étude de marketing la plus privilégiée était une enquête auprès des consommateurs potentiels dans les points de vente.
Questions et tâches
1. Quels types de points de vente faut-il rechercher ?
2. Quelle méthode d'échantillonnage des points de vente est la plus préférable dans cette situation (probabiliste ou déterministe) ?
3. Quels sont les critères de sélection des répondants qui participeront à l'enquête ?
4. Travaux pratiques"Détermination de la base de sondage"
But du travail: Explorer les méthodes permettant de déterminer la base de sondage et la taille de l'échantillon.
Le contenu de l'ouvrage: Les étudiants reçoivent des listes de tâches de recherche. Les questions de recherche peuvent être simples et liées à des produits familiers aux étudiants. Par exemple, combien de barres de chocolat un étudiant en économie dans une université consomme-t-il en moyenne par semaine ? Pour cela, les élèves doivent construire une base de sondage (en supposant que la base de sondage et la population cible sont identiques) en remplissant le tableau. 18.
Tableau 18
Population hypothétique pour étudier la consommation de barres chocolatées
Cependant, il convient de prêter attention au fait que les valeurs maximales et minimales ne doivent pas être considérées comme dépassant de manière significative le nombre moyen de barres consommées. À l'aide d'un tableau de nombres aléatoires (annexe 13), les étudiants doivent, sans recourir à une enquête auprès de l'ensemble de la population, déterminer combien de barres de chocolat les étudiants de la Faculté d'économie de l'université consomment en moyenne par semaine.
5. Exemples de résolution de problèmes typiques17
Compilé par: Davis D. Recherche en activités publicitaires : théorie et pratique / Trad. de l'anglais – M. : Williams, 2003. – pp.
Exemple 1. Déterminez la taille finale de l’échantillon si trois questions alternatives nécessitant une réponse « d’accord ou pas d’accord » ont été élaborées pour la recherche. La première question devrait recevoir une réponse affirmative de 10 % de l'échantillon, la deuxième de 20 % et la troisième de 85 %. De plus, il est nécessaire de garantir un intervalle de confiance étroit ne dépassant pas ± 3 % pour chacune des trois questions séparément.
Solution. Pour résoudre ce problème il faut utiliser les données de l’annexe. 4. D'après le tableau présenté en annexe. 4, il apparaît clairement qu'avec un intervalle de confiance d'une valeur n'excédant pas ±3% avec la proportion attendue de réponses affirmatives :
– 10 % – la taille de l'échantillon doit être de 400 ;
– 20 % – la taille de l'échantillon doit être de 700 ;
– 85 % – la taille de l’échantillon devrait être d’environ 600 personnes.
Par conséquent, la taille finale de l'échantillon à ces valeurs devrait être de 700 personnes (la plus grande des trois tailles d'échantillon requises).
Répondre: 700 personnes.
Exemple 2. Supposons que vous ayez besoin d'obtenir une réponse d'un groupe de personnes interrogées à la question : « Connaissez-vous la publicité pour les gâteaux produits par Zhuravli Factory-Kitchen OJSC ? », en espérant recevoir une réponse affirmative de 35 % des personnes interrogées. Dans ce cas, vous devez être sûr à 99 % que la proportion réelle de réponses positives se situera dans une fourchette de ±2 %. Quelle serait la taille de l’échantillon si le niveau de confiance est de 95 % et l’intervalle de confiance de ±4 % ?
Solution. La taille d'échantillon requise à un niveau de confiance donné est déterminée par la formule :

p – part attendue ;
e – intervalle de confiance souhaité.
Les scores Z pour différents niveaux de confiance sont présentés dans le tableau. 19.
Tableau 19
Valeur du score Z
En substituant les valeurs, on obtient :
La taille de l'échantillon est grande car le niveau de confiance et l'intervalle de confiance établissent un niveau de précision élevé. La taille de l’échantillon sera beaucoup plus petite si l’intervalle de confiance augmente à ±4 % et si le niveau de confiance diminue à 95 % :

Répondre: 3756 personnes ; 546 personnes
Exemple 3. Supposons que la population soit de 375 557 personnes. Il est nécessaire de déterminer la taille de l'échantillon, si le niveau de confiance est de 95 %, l'intervalle de confiance est de ±0,05.
Solution.
Nous présentons la solution à ce problème sous forme de tableau. 20.
Tableau 20
Détermination de la taille de l'échantillon

Répondre: 350 personnes
Exemple 4. Imaginez la situation suivante. Vous vous êtes adressé à un groupe de personnes interrogées avec une demande : « Veuillez évaluer la crédibilité de la publicité du salon informatique d'OJSC « Supercomp » sur une échelle de un à cinq. Quelle serait la taille de l’échantillon si vous vouliez être sûr à 95 % que la véritable note moyenne de la population se situerait à ± 0,4 de la moyenne de l’échantillon ?
Solution.
Dans un premier temps, nous évaluerons l'écart type. Il peut être obtenu en additionnant les valeurs extrêmes de l'échelle et en divisant la somme par quatre :
s = (5 + 1) : 4 = 1,5
La taille d'échantillon requise pour un niveau de confiance souhaité donné peut être calculée à l'aide de la formule :

où z est le score z correspondant au niveau de confiance requis ;
e – intervalle de confiance souhaité ;
s 2 – écart type.
Répondre: 54 personnes
6
Tache 1. Remplissez les espaces vides du tableau. 21, indiquant les avantages et les inconvénients des méthodes d’échantillonnage.
Tableau 21
Analyse comparative des méthodes d'échantillonnage

Problème 2. Pour chacune des situations suivantes, déterminez la population cible :
a) OJSC « Dairy Plant » souhaite recevoir des informations sur les raisons de la faible activité des acheteurs de produits laitiers dans les campagnes publicitaires de l'usine ;
b) un grossiste engagé dans la vente d'appareils électroménagers dans la ville de N souhaite évaluer la réaction des consommateurs à une campagne visant à stimuler la vie quotidienne ;
c) Le grand magasin central de la ville souhaite recevoir des informations sur l'efficacité des annonces placées dans le journal local ;
d) un fabricant national de cosmétiques souhaite s'assurer que les grossistes disposent de stocks suffisants pour éviter les ruptures de stock chez les détaillants ;
e) le café universitaire compte tester une nouvelle boisson gazeuse produite par ses salariés.
Tâche 3. L'administration d'une station touristique populaire a décidé de déterminer l'attitude des touristes qui visitent la station à l'égard de certains types de loisirs actifs. Il était prévu qu'un avis soit distribué dans chaque chambre des deux plus grands hôtels de la station, informant les clients du but, de l'heure et du lieu de l'étude. Les personnes souhaitant participer à l'enquête devaient se rendre dans le hall de l'hôtel, où il était prévu d'installer des tables spéciales :
a) quelle méthode est utilisée pour sélectionner les éléments de l’échantillon ?
Tâche 4. La direction de l’entreprise Bogatyr, fabricant de vêtements grandes tailles, a décidé de modifier la stratégie marketing de l’entreprise. Cette opération a été précédée d'une série d'enquêtes auprès de groupes cibles. Les groupes interrogés étaient composés de 10 à 12 hommes et femmes de grande taille présentant des caractéristiques démographiques différentes, sélectionnés en fonction de leurs caractéristiques physiques directement dans la rue :
a) par quelle méthode les éléments de l'échantillon sont-ils sélectionnés ?
b) donner une évaluation critique de la méthode de sélection utilisée.
Tâche 5. Le pourcentage de familles disposant d'un lecteur DVD et la durée moyenne d'utilisation au cours de la semaine sont déterminés. Le niveau de précision requis est de 95 %, l'erreur maximale est de ±3 % pour le nombre de propriétaires et de ±1 heure pour la durée d'utilisation. Une étude précédente a révélé que 20 % des ménages possédaient des lecteurs DVD ; la durée moyenne d'utilisation est de 15 heures par semaine avec un écart type de 5 heures :
a) quelle devrait être la taille de l’échantillon pour déterminer le nombre de ménages équipés de lecteurs DVD ?
b) quelle devrait être la taille de l'échantillon pour déterminer le temps moyen passé à utiliser les lecteurs de DVD ?
c) quelle devrait être la taille de l’échantillon pour déterminer les deux paramètres ci-dessus ? Pourquoi?
Tâche 6. La population générale est décrite par les caractéristiques suivantes (tableau 22). Sur la base de ces trois critères, déterminez les performances d’un échantillon de 200 éléments.
Tableau 22
Caractéristiques de la population

Problème 7. OJSC "Beer" envisage de changer l'étiquette de ses principaux produits :
a) identifier la population et la base de sondage qui peuvent être utilisées dans ce cas ;
b) décrire comment obtenir un échantillon aléatoire simple en utilisant votre base de sondage établie ;
c) Est-il possible de procéder à un échantillonnage stratifié ? Si oui, comment ?
d) est-il possible d'utiliser l'échantillonnage en grappes ? Si oui, comment ?
e) quelle méthode d'échantillonnage recommandez-vous ? Pourquoi?
Tâche 8. Remplissez le tableau. 23, précisant les critères qui déterminent l’opportunité de recourir à un échantillon ou à un recensement.
Tableau 23
Critères permettant de déterminer si un échantillon ou un recensement est approprié

Tâche 9. Quel effet une réduction de 25 % de l’exactitude absolue de la moyenne générale aurait-elle sur la taille de l’échantillon ? Réduire le niveau de confiance de 95 à 90 % ?
Problème 10. Supposons que vous ayez besoin d'obtenir une réponse d'un groupe de personnes interrogées à la question : « Connaissez-vous la publicité pour les yaourts à boire produits par OJSC Dairy Plant ? », en vous attendant à recevoir une réponse affirmative de 45 % des personnes interrogées. Dans ce cas, vous devez être sûr à 99 % que la proportion réelle de réponses positives se situera dans une fourchette de ±3 %. Quelle serait la taille de l’échantillon au niveau de confiance de 95 % et à l’intervalle de confiance de ± 4 % ?
Problème 11. Imaginez la situation suivante. Vous vous êtes tourné vers un groupe de personnes interrogées avec une demande : « Veuillez évaluer la crédibilité des meubles d'armoires publicitaires produits par l'entreprise de meubles Katyusha sur une échelle de un à cinq. Quelle serait la taille de l’échantillon si vous vouliez être sûr à 95 % que la valeur réelle de la note moyenne de la population se situerait à ± 0,5 de la moyenne de l’échantillon ?
Problème 12. Déterminez la taille finale de l’échantillon si trois questions alternatives nécessitant une réponse « d’accord ou pas d’accord » ont été élaborées pour la recherche. La première question devrait recevoir une réponse affirmative de 20 % de l'échantillon, la deuxième de 35 % et la troisième de 65 %. De plus, il est nécessaire de fournir un intervalle de confiance étroit, qui se situe à ± 4 % pour chacune des trois questions séparément.
7. Discussion
Lisez et discutez les déclarations suivantes :
1. Plus les différences (hétérogénéité) au sein de la population sont grandes, plus l’erreur d’échantillonnage possible est importante.
2. La taille de l'échantillon dépend du niveau d'homogénéité ou d'hétérogénéité des objets étudiés. Plus ils sont homogènes, plus les nombres sont petits et permettent de tirer des conclusions statistiquement fiables.
3. La détermination de la taille de l'échantillon dépend du niveau de l'intervalle de confiance de l'erreur statistique tolérée. Il s'agit des erreurs dites aléatoires associées à la nature de toute erreur statistique.
4. Le résultat le plus fiable, sous certaines conditions, peut être obtenu par une étude continue ou un recensement.
5. Chaque échantillon présente un certain niveau de représentativité et un taux d'erreur associé.
6. Il existe une certaine limite de taille d’échantillon, dont le dépassement n’augmente pas de manière significative la précision des résultats.
7. Les exigences les plus « douces » sont imposées à l’échantillon d’une étude à des fins de renseignement. Le grand principe ici est d’identifier les groupes « polaires » selon des critères indispensables à l’analyse. La taille de ces échantillons n’est pas strictement déterminée. La collecte d'informations se poursuit jusqu'à ce que le chercheur accumule une variété d'informations non représentatives, mais tout à fait suffisantes pour formuler des hypothèses.
8. L’échantillonnage stratifié est plus précis que l’échantillonnage aléatoire simple.
9. La plupart des cas de falsification involontaire de données surviennent au stade de l'échantillonnage. Il existe peu de spécialistes compétents en matière d'échantillonnage en Russie, de sorte que même dans certaines entreprises bien connues, l'échantillonnage n'est pas élaboré de manière suffisamment professionnelle.
10. Toutes les méthodes de recherche comportent des erreurs potentielles. Et personne ne peut en être à l’abri. La solution est de s'engager systématiquement dans des études de marché et à un niveau professionnel. L'expérience et les connaissances vous permettront alors de surmonter avec succès la plupart des goulots d'étranglement. 18
Tokarev B.E. Recherche en marketing. – M. : Économiste, 2007. – P. 582-583.
8. Essai de contrôle
1. Selon vous, quels sont les avantages ou les inconvénients de l’observation sélective en marketing ? _______________________________.
2. L'observation d'échantillons permet-elle d'étudier tout ou partie des unités de la population ?
a) fournit :
b) fournit partiellement ;
c) Je ne sais pas.
3. L'échantillonnage vous permet-il d'économiser de l'argent sur la réalisation d'une enquête ?
a) permet ;
b) ne le permet pas.
4. Une enquête partielle fournit-elle des informations complètes ?
a) a ;
b) n'a pas.
5. L'observation d'un échantillon permet-elle de juger de manière fiable l'ensemble de la population par sa partie ?
c) Je ne sais pas.
Thème 5. FORMULAIRE DE COLLECTE DE DONNÉES
1. Problèmes à résoudre de manière autonome
Problème 1. Identifiez le type d’échelle utilisé dans chacune des questions suivantes. Justifiez votre réponse:
a) à quelle période de l’année planifiez-vous habituellement vos vacances ?
b) le revenu total de votre famille ? _________________.
c) Quelles sont vos trois marques de shampoing préférées ? Notez-les de 1 à 3 selon vos préférences, en attribuant 1 comme étant votre préféré :
– Pantène Pro-V ;
d) combien de temps passez-vous chaque jour sur le trajet entre la maison et l'université :
– moins de 5 minutes ;
– 5 à 15 minutes ;
– 16 à 20 minutes ;
– 21 à 30 minutes ;
– 30 minutes ou plus ;
e) dans quelle mesure êtes-vous satisfait du magazine « Marketing et publicité » :
- Très satisfait;
- satisfait;
– à la fois satisfaits et insatisfaits ;
– insatisfait;
- très mécontent ;
f) combien de cigarettes fumez-vous par jour en moyenne ?
– plus d'un paquet ;
– d'un demi-paquet à un tout ;
– moins d'un demi-paquet ;
g) votre niveau d'études :
– secondaire inachevé ;
– terminé le secondaire;
– des études supérieures inachevées ;
- avoir terminé des études supérieures.
Problème 2. Vous trouverez ci-dessous une analyse pour chacune des questions précédentes. L’analyse utilisée est-elle adaptée au type d’échelle de mesure dans chaque cas ?
R. Environ 50 % de l'échantillon part en vacances à l'automne, 25 % au printemps et les 25 % restants en hiver. On peut en conclure qu'à l'automne, il y a deux fois plus de vacanciers qu'au printemps et en hiver.
B. Le revenu total moyen d'un membre de la famille est de 15 000 roubles. Répondants dont le revenu total est inférieur à 15 000 roubles. 67%, avec un revenu de plus de 15 000 roubles. – 33%.
Q. Pantene Pro-V est la marque préférée. Sa valeur de préférence moyenne est de 3,52. D. La valeur médiane de toutes les options de réponse concernant le temps passé à voyager du domicile à l'université est de 8,5 minutes. Trois fois plus de personnes interrogées passent moins de 5 minutes sur la route par rapport à celles qui y passent 16 à 20 minutes.
D. Le score de satisfaction moyen est de 4,5, ce qui semble indiquer le niveau élevé de satisfaction reçu par les lecteurs du magazine Marketing et Publicité.
E. 10 % des répondants fument moins d'un demi-paquet de cigarettes par jour, tandis que 90 % des répondants fument plus d'un paquet par jour.
G. Les réponses montrent que 40 % des personnes interrogées ont un enseignement secondaire incomplet, 25 % ont un diplôme d'études secondaires, 20 % ont un enseignement supérieur incomplet et 15 % sont diplômés d'établissements d'enseignement supérieur.
Tâche 3. L'agence de publicité MIR a l'intention d'étudier le niveau de notoriété et de perception des consommateurs d'une campagne publicitaire développée pour OJSC Dairy Plant. Il a été décidé de mener des recherches quantitatives. Le public cible de la publicité et, par conséquent, la population échantillon de l'étude étaient des femmes âgées de 20 ans et plus, vivant dans la ville de N et ayant actuellement des enfants de moins de 10 ans. La campagne publicitaire a été réalisée pour informer les consommateurs sur les nouveaux produits destinés aux aliments pour bébés. Votre client, OJSC Dairy Plant, souhaite savoir si le but de la recherche doit être caché au répondant. Quelles questions poserez-vous au directeur marketing de Dairy Plant OJSC et de quelles informations avez-vous besoin pour prendre une décision ? Quels facteurs influenceront votre décision de ne pas divulguer l'objectif de l'étude lors de l'élaboration d'un questionnaire pour l'usine laitière OJSC ? Quels sont les avantages et les inconvénients de dissimuler le but de la recherche lors de la réalisation de ce projet de recherche ?
a) lequel des journaux suivants lisez-vous régulièrement :
- « ouvrier de Briansk » ;
- "TVNZ" ;
– « Journal économique » ;
b) à quelle fréquence achetez-vous des produits auprès de l'OJSC « Dairy Plant » :
c) vous acceptez que le gouvernement devrait imposer des restrictions à l'importation sur :
- Je suis tout à fait d'accord ;
- accepter;
– ni contre ni pour ;
– Je ne suis pas d'accord ;
- définitivement, - pas d'accord ;
d) à quelle fréquence achetez-vous la lessive Cif :
- une fois par semaine;
- une fois toutes les deux semaines ;
– une fois toutes les trois semaines ;
- une fois par mois;
d) à quel groupe social appartenez-vous ?
- ouvrier;
- employé;
- directeur;
- autre;
f) où achetez-vous habituellement des fournitures de bureau ?
g) quand vous regardez la télévision, regardez-vous des publicités ?
i) quelle marque de thé connaissez-vous le plus :
j) que pensez-vous que le gouvernement russe devrait, dans le contexte de la crise financière mondiale, poursuivre la politique actuelle de réduction des impôts et des dépenses publiques :
k) à quelle fréquence pendant la semaine faites-vous de l'exercice :
- tous les jours;
– 5 à 6 fois par semaine ;
– 2 à 4 fois par semaine ;
- une fois par semaine;
a) laquelle des raisons suivantes est la plus importante pour vous lors du choix d'un téléviseur :
– le service en magasin ;
- marque déposée ;
– niveau de défauts ;
- les garanties ;
b) indiquez votre niveau d'études :
- moins que le secondaire;
– secondaire inachevé ;
- lycée;
– technique secondaire ;
– des études supérieures inachevées ;
– avoir effectué des études supérieures ;
– professionnel supérieur ;
c) quel est votre revenu mensuel moyen :
– moins de 4 500 RUB ;
– 4 501 à 10 000 RUB ;
– 10 001 à 20 000 roubles ;
– 20 001 à 50 000 roubles ;
– plus de 50 001 roubles ;
d) votre revenu mensuel moyen ?
- haut;
- moyenne;
– minime.
Tâche 6. Sélectionnez au moins cinq marques de la même gamme de produits provenant de fabricants renommés, par exemple du shampoing, des voitures, du chocolat, etc. Énumérez 5 à 10 paramètres (propriétés, qualités) par lesquels ces produits peuvent être évalués, puis :
Tableau 24
Résultats de l’évaluation à l’échelle à somme constante

c) modifier le tableau. 25, attribuant un rang à chaque paramètre en fonction de sa signification, allant de 0 (le moins préférable) à 1 (le plus préférable), résume les résultats dans le tableau. 25, tirer une conclusion, comparer avec les résultats des tâches précédentes ;
Tableau 25
Résultats de l'évaluation sur une échelle à somme constante tenant compte du rang

d) évaluez ces produits sur une échelle de Likert modifiée en utilisant sept options d'évaluation : 7 – merveilleux ; 6 – très bien ; 5 – bien ; 4 – médiocre ; 3 – mauvais ; 2 – très mauvais ; 1 – sans valeur (tableau 26) ;
Tableau 26
Résultats modifiés de l’évaluation sur l’échelle de Likert

Tableau 27
Comparaison des produits par paramètre a (b, c, …)

Déterminez le nombre de cas de préférence pour chaque produit par rapport à tous les autres produits :

où f Si est le nombre total de préférences pour le produit Si par rapport aux autres produits (déterminé en comptant le nombre d'« unités » dans la ligne correspondante dans tous les tableaux) ;
n – nombre de marchandises ;
m – nombre de paramètres selon lesquels l'évaluation est effectuée ;
f ksij – fréquence (évaluation) du choix du produit S i de préférence au produit S j.
Calculez le poids généralisé pour chaque produit :
où W est le poids généralisé du produit S en fractions d'unité ();
J – nombre total de notes reçues :

Multipliez les poids généralisés par 100 et comparez-les avec les résultats des devoirs précédents.
Tâche 7. Sélectionnez cinq marques de différents fabricants de n'importe quel groupe de produits (par exemple, produits laitiers, chocolat, café, etc.). Rédigez des questions sur cette gamme de marques étudiées en utilisant des échelles nominales, ordinales, d'intervalle et de ratio. Répondez aux questions proposées. Quelles sont les questions auxquelles il est plus difficile de répondre et pourquoi ?
Problème 8. Les étudiants doivent se diviser en groupes de trois à quatre personnes. En utilisant la méthode des comparaisons par paires, chaque membre du groupe doit évaluer cinq à six publicités télévisées selon des critères tels que l'originalité de l'idée de l'auteur, la mémorisation et la motivation du consommateur à acheter. Il faut ensuite évaluer le degré de cohérence des avis, calculer la note intégrale des vidéos et déterminer la meilleure.
Tâche 9.À l'aide de la méthode de comparaison par paires pour le compte de trois experts, évaluez cinq marques de thé en fonction de critères tels que l'arôme, la richesse, le goût et le prix. Conformément à leur avis, calculez la note intégrale du thé et déterminez le meilleur.
Problème 10. Calculez l'évaluation intégrale subjective de 10 sites Web des plus grandes sociétés russes d'études de marché selon les critères suivants : exhaustivité des informations sur les services fournis, exhaustivité des informations sur l'entreprise, conception, facilité de navigation. Déterminez l’importance de ces caractéristiques.
Problème 11. Développer une échelle différentielle sémantique pour mesurer l’image de deux universités de la ville. Présentez votre échelle à un échantillon pilote de 20 étudiants. Sur la base de vos recherches, répondez à la question : Quelle université a une image la plus favorable ? Quelles autres méthodes peuvent être utilisées pour évaluer l’image des universités ?
Problème 12. Développez une échelle de Likert pour mesurer l’image de deux banques de votre ville. Présentez cette échelle à un échantillon pilote de 20 étudiants. Sur la base de vos recherches, répondez à la question : quelle banque a une image la plus favorable ?
Problème 13. Développer une échelle Stapel pour mesurer l’image de deux chaînes de vente au détail urbaines. Présentez cette échelle à un échantillon pilote de 20 étudiants. Sur la base de vos recherches, répondez à la question : Quelle chaîne a une image la plus favorable ?
Problème 14.Élaborer un questionnaire pour déterminer comment les étudiants choisissent leur destination de vacances. Pré-testez le questionnaire en le présentant à 10 étudiants lors d’entretiens personnels. Comment modifieriez-vous le questionnaire après le prétest ?
Problème 15. En décembre 2008, dans l'une des cliniques de la ville A, un registre électronique unique est apparu, qui permet aux patients de prendre rendez-vous à une heure qui leur convient, en contournant le système habituel : lever à six heures du matin - file d'attente - coupon. Extérieurement, le registre électronique, ou kiosque d'information, est similaire à un guichet automatique ordinaire. Il est situé au premier étage de la clinique, juste à l'entrée. Chacun peut saisir son numéro d'assurance maladie et consulter sur l'écran les horaires d'ouverture d'un établissement médical et/ou d'un spécialiste spécifique, ainsi que prendre rendez-vous. Les femmes ont également accès à des informations sur les horaires d'accueil de la clinique prénatale située à l'autre bout de la ville, ainsi que sur les horaires de travail des pédiatres de la clinique pour enfants. Un professionnel surveille ce qui se passe sur l’écran à la réception. Le kiosque fonctionnant en ligne, les informations demandées dans le registre sont enregistrées, analysées et systématisées. La carte ambulatoire du patient est envoyée au cabinet du médecin dont il a besoin et les informations à ce sujet sont ajoutées à la base de données. 19
Privalenko O. Je prendrai moi-même rendez-vous avec le médecin // Arguments et faits. – 2008. – n° 51 (376).
Quelle méthode de collecte de données est utilisée dans cette situation ? Comment utiliser les informations obtenues ? Comment peut-il améliorer l’efficacité de la clinique ?
Problème 16. L'entreprise est un magasin de détail spécialisé « Coffee Paradise ». Le but de l’étude marketing est de comprendre comment la consommation de café va évoluer au cours des deux prochaines années. L'entreprise prévoit d'utiliser les méthodes suivantes :
– des groupes de discussion avec des consommateurs – réels et potentiels ;
– des entretiens approfondis et une enquête de masse auprès des amateurs de café et des non-buveurs de café, évaluation des facteurs influençant leur choix.
L'entreprise souhaite obtenir des informations sur la capacité du marché et sa dynamique ; motivation des consommateurs de café ; description des situations d'achat et de consommation de café, évaluation de la demande par segment, son élasticité-prix. Il est prévu que l'étude aboutisse à des modèles de comportement des consommateurs ; prévu pour 2 à 4 ans ; clarification du positionnement de la marque, justification de la stratégie tarifaire ; formation du concept du programme de promotion de la marque. Vous travaillez en tant que spécialiste du marketing pour une entreprise et vous êtes chargé de développer des formulaires pour collecter des informations.
Problème 17.À l'aide de la fiche d'observation (Annexe 6), réalisez une étude pour connaître le nombre, le sexe et l'âge des clients visitant le magasin. Quelles conclusions peut-on tirer des résultats de l’observation ? Quelles modifications peuvent être apportées au formulaire d'observation ?
Problème 18. La direction de l'usine de transformation de viande a été confrontée à une baisse des ventes et a décidé d'en étudier les raisons au plus vite. Il a été décidé de réaliser un entretien personnel dont le questionnaire est présenté en annexe. 7.
Problème 19.À la question directe « Avez-vous un lecteur DVD ? » 72% de réponses positives ont été données. Et à la question indirecte « Allez-vous acheter un lecteur DVD dans un avenir proche ? 57% des personnes interrogées ont déclaré avoir déjà un joueur. Cependant, il y a eu beaucoup moins de réponses positives qu’avec la première version de la question. Expliquer les inconvénients des enquêtes directes et les avantages des enquêtes indirectes.
Problème 20. Supposons que vous travailliez pour une agence de marketing qui vous a confié la tâche de développer un formulaire de suivi du personnel de service d'une des entreprises de fenêtres en plastique. En d'autres termes, vous et vos collègues devez visiter l'entreprise sous la forme d'un client ordinaire, poser des questions « d'achat » typiques basées sur la « légende » convenue avec le client et peut-être même acheter quelque chose. Sur la base des résultats de la visite à l'extérieur de l'entreprise, vous devez remplir un questionnaire détaillé. Le questionnaire peut contenir de 15 à 35 paramètres sur lesquels le personnel de l'entreprise doit être évalué. Composez un questionnaire en utilisant les paramètres suivants : respect des normes d'apparence de l'entreprise (code vestimentaire) ; connaissance des produits vendus, de leurs propriétés et caractéristiques de consommation ; compétences en présentation de produits; compétences en service à la clientèle (ou compétences actives en vente et en communication commerciale); mise en place des campagnes marketing en cours (produit du jour, vente de cartes de réduction, promotion de nouvelles marques, etc.). Si nécessaire, ajoutez de nouveaux paramètres au questionnaire. Répondez également aux questions.
Chaque chercheur peut créer sa propre échelle, mais cela n'en vaut guère la peine. Il est préférable de choisir une échelle parmi les échelles standards qui sont originales dans le sens où elles ont leur propre nom, sont largement utilisées et sont incluses dans le système d'échelles le plus couramment utilisé. Ils sont aussi appelés originaux. Ensuite, quatre échelles de notation discrètes sont considérées : Likert, différentielle sémantique, notation graphique et Stepel, ainsi qu'une échelle à somme constante et une échelle de classement.
échelle de Likert basé sur le choix du degré d’accord ou de désaccord avec une déclaration spécifique. En fait, un pôle de cette échelle ordinale essentiellement bipolaire est formulé, ce qui est beaucoup plus simple que de nommer les deux pôles. La formulation de l'énoncé peut correspondre au niveau idéal de certains paramètres de l'objet. Pour caractériser un établissement d'enseignement supérieur, on peut considérer ses propriétés suivantes : personnel enseignant qualifié, salles de classe équipées de moyens techniques, modernité et régularité de la mise à jour des formations, disponibilité e-leming en technologies éducatives, niveau de culture, image et réputation, population étudiante et bien d’autres. La formulation des déclarations pourrait être la suivante : le personnel enseignant de cette université est très qualifié ; l'université a un très haut niveau d'utilisation des supports pédagogiques modernes ; cette université forme des étudiants en quête de connaissances ; les diplômés de cette université sont très appréciés sur le marché du travail.
Lorsqu’on utilise une échelle de Likert, cinq gradations sont généralement prises en compte. Un exemple d'utilisation d'une échelle de Likert dans un questionnaire est présenté dans la Fig. 8.1. En d’autres termes, les questions sont formulées selon un format d’échelle de Likert. Le répondant est invité à cocher une des cinq cases.
Riz. 8.1.
Dans ce cas, l'évaluation quantitative elle-même n'est pas exigée du répondant, même si le plus souvent des points peuvent être immédiatement attribués à côté des noms des gradations. Comme on peut le voir sur la Fig. 8.1, le degré d'accord ou de désaccord avec chaque affirmation formulée peut avoir les gradations suivantes : fortement en désaccord (1 point), en désaccord (2 points), neutre (3 points), d'accord (4 points), tout à fait d'accord (5 points). Ici, entre parenthèses, se trouve l’option la plus couramment utilisée pour numériser la balance. Il est également possible qu'un score plus élevé (5 points) corresponde à la gradation « pas du tout d'accord ».
Échelle de notation différentielle sémantique et graphique
Échelle différentielle sémantique présuppose la présence de deux sens sémantiques polaires (antonymes) ou positions antonymiques, entre lesquelles il existe un nombre impair de gradations. En ce sens, l’échelle est bipolaire. En règle générale, sept gradations sont considérées. La position médiane (gradation médiane) est considérée comme neutre. La numérisation des gradations d'échelle peut être unipolaire, par exemple sous la forme "1, 2, 3, 4, 5, 6, 7", ou bipolaire, par exemple sous la forme "-3, -2, -1, 0, 1, 2, 3".
Habituellement, les pôles de la balance sont spécifiés verbalement (verbal). Des exemples d'échelles à deux pôles sont les suivants : « apaisant – tonifiant » ou « compact – volumineux ». Parallèlement aux différentiels sémantiques verbaux, des différentiels sémantiques non verbaux ont été développés qui utilisent des images graphiques comme pôles.
Des exemples de différentiels sémantiques verbaux sont donnés dans la Fig. 8.2.

Riz. 8.2.
Le différentiel sémantique ressemble à l'échelle de Likert, mais présente les différences suivantes : 1) les deux énoncés polaires sont formulés au lieu d'un seul ; 2) au lieu des noms des gradations intermédiaires, une disposition graphique séquentielle d'un nombre impair de gradations situées entre les valeurs extrêmes « bon - mauvais » est donnée.
Méthode différentielle sémantique (du grec. sématique – désignant et lat. différence différence) a été proposée par le psychologue américain Charles Osgood en 1952 et est utilisée dans les études liées à la perception et au comportement humains, avec l'analyse des attitudes sociales et des significations personnelles, en psychologie et en sociologie, dans la théorie des communications de masse et de la publicité, et dans commercialisation.
Peut être considéré comme un analogue de l'échelle différentielle sémantique. L'échelle de notation est réalisée de telle sorte que chaque propriété est associée à une ligne dont les extrémités correspondent à des énoncés polaires, par exemple : « pas important » et « très important », « bon » et « mauvais » (Fig. 8.3).
Riz. 8.3.
La différence fondamentale entre les échelles comparées est que la différentielle sémantique est une échelle discrète et, en règle générale, comporte sept gradations et que l'échelle d'évaluation graphique est continue.
- Ainsi, lorsqu'on caractérise l'extérieur de certaines marques de voitures, on dit parfois qu'il se caractérise par la brutalité. Il existe également des exemples plus simples - l'ergonomie et la contrôlabilité, lorsqu'il est difficile de nommer de manière significative le deuxième pôle.
E.P. Golubkov Académicien de l'Académie internationale de l'informatisation, docteur en économie, professeur à l'Académie d'économie du gouvernement de la Fédération de Russie
1. Échelles de mesure
Pour collecter des données, des questionnaires sont élaborés. Les informations pour les remplir sont collectées en prenant des mesures. Par mesure, nous entendons la détermination d'une mesure quantitative ou de la densité d'une certaine caractéristique (propriété) intéressant le chercheur.
La mesure est une procédure permettant de comparer des objets selon certains indicateurs ou caractéristiques (attributs).
Les mesures peuvent être de nature qualitative ou quantitative et peuvent être objectives ou subjectives. Les mesures objectives qualitatives et quantitatives sont réalisées par des instruments de mesure dont le fonctionnement repose sur l'utilisation de lois physiques. La théorie des mesures objectives est assez bien développée.
Les mesures subjectives sont effectuées par une personne qui, pour ainsi dire, fait office d'appareil de mesure. Naturellement, avec une mesure subjective, ses résultats sont influencés par la psychologie de la pensée d’une personne. Une théorie complète des mesures subjectives n’a pas encore été construite. Cependant, nous pouvons parler de la création d'un schéma formel général pour les mesures objectives et subjectives. Basée sur la logique et la théorie des relations, une théorie des mesures a été construite, qui permet d'envisager à la fois les mesures objectives et subjectives à partir d'une position unifiée.
Toute mesure comprend : des objets, des indicateurs et une procédure de comparaison.
Les indicateurs (caractéristiques) de certains objets (consommateurs, marques de produits, magasins, publicité, etc.) sont mesurés. Les propriétés et caractéristiques spatiales, temporelles, physiques, physiologiques, sociologiques, psychologiques et autres des objets sont utilisées comme indicateurs pour comparer des objets. La procédure de comparaison consiste à définir les relations entre les objets et la manière dont ils sont comparés.
L'introduction d'indicateurs de comparaison spécifiques permet d'établir des relations entre des objets, par exemple « plus », « moins », « égal », « pire », « préférable », etc. Il existe différentes manières de comparer des objets entre eux, par exemple séquentiellement avec un objet pris comme standard, ou les uns avec les autres dans une séquence aléatoire ou ordonnée.
Une fois qu'une caractéristique a été déterminée pour un objet sélectionné, l'objet est dit avoir été mesuré par rapport à cette caractéristique. Les propriétés objectives (âge, revenus, quantité de bière bue, etc.) sont plus faciles à mesurer que les propriétés subjectives (sentiments, goûts, habitudes, relations, etc.). Dans ce dernier cas, le répondant doit traduire ses notes en une échelle de densité (un système numérique) que le chercheur doit développer.
Les mesures peuvent être prises à l'aide de différentes échelles. Il existe quatre caractéristiques des échelles : la description, l'ordre, la distance et la présence d'un point de départ.
La description suppose l'utilisation d'un seul descripteur ou identifiant pour chaque gradation de l'échelle. Par exemple, « oui » ou « non » ; "accord ou désaccord"; âge des répondants. Toutes les échelles comportent des descripteurs qui définissent ce qui est mesuré.
L'ordre caractérise la taille relative des descripteurs (« supérieur à », « inférieur à », « égal »). Toutes les échelles n'ont pas de caractéristiques d'ordre. Par exemple, on ne peut pas dire plus ou moins « acheteur » par rapport à « non-acheteur ».
Une caractéristique d'échelle telle que la distance est utilisée lorsque la différence absolue entre les descripteurs est connue, qui peut être exprimée en unités quantitatives. Un répondant qui a acheté trois paquets de cigarettes en a acheté deux de plus qu'un répondant qui n'en a acheté qu'un seul. Il convient de noter que lorsque la « distance » existe, l’ordre existe aussi. Le répondant qui a acheté trois paquets de cigarettes en a acheté « plus » que le répondant qui n’en a acheté qu’un seul. La distance dans ce cas est de deux.
Une échelle est considérée comme ayant un point de départ si elle a une seule origine ou un point zéro. Par exemple, l’échelle d’âge a un véritable point zéro. Cependant, toutes les échelles n’ont pas de point zéro pour les propriétés mesurées. Souvent, ils n’ont qu’un point neutre arbitraire. Par exemple, répondant à une question sur la préférence d'une certaine marque de voiture, le répondant a répondu qu'il n'avait pas d'opinion. La gradation « Je n'ai pas d'opinion » ne caractérise pas le véritable niveau zéro de son opinion.
Chaque caractéristique suivante de l'échelle est construite sur la caractéristique précédente. Ainsi, la « description » est la caractéristique la plus fondamentale inhérente à toute échelle. Si une échelle a une « distance », elle a également un « ordre » et une « description ».
Il existe quatre niveaux de mesure qui déterminent le type d'échelle de mesure : noms, ordre, intervalle et rapports. Leurs caractéristiques relatives sont données dans le tableau. 1.
Tableau 1
Caractéristiques des différents types de balances
L'échelle de dénomination n'a que la caractéristique de description ; il attribue uniquement son nom à l'objet décrit ; aucune caractéristique quantitative n'est utilisée. Les objets de mesure appartiennent à de nombreuses catégories mutuellement exclusives et exhaustives. L'échelle de dénomination établit des relations d'égalité entre les objets regroupés en une seule catégorie. Chaque catégorie reçoit un nom dont la désignation numérique est un élément de l'échelle. Bien entendu, une mesure à ce niveau est toujours possible. « Oui », « Non » et « D'accord », « Pas d'accord » sont des exemples de gradations de telles échelles. Si les répondants ont été classés selon le type de leur activité (échelle de nom), alors cela ne fournit pas d'informations sur le type ; « plus que », « moins que ». Dans le tableau 2 fournit des exemples de questions formulées à la fois dans l'échelle de noms et dans d'autres échelles.
Tableau 2
Exemples de questions formulées dans différentes échelles de mesure
A. Échelle des noms
1. Veuillez indiquer votre sexe : homme, femme
2. Sélectionnez les marques de produits électroniques que vous achetez habituellement :
-Sony
-Panasonique
-Phillips
-Orion
-etc.
3. Etes-vous d'accord ou en désaccord avec l'affirmation selon laquelle l'image de la société Sony repose sur la production de produits de haute qualité ? Je suis d'accord Je ne suis pas d'accord
B. Barème de commande
1. Veuillez classer les fabricants de produits électroniques selon votre système de préférences. Mettez « 1 » pour l'entreprise qui se classe en première position dans votre système de préférences ; « 2 » – seconde, etc. :
-Sony
-Panasonique
-Phillips
-Orion
-etc.
2. Pour chaque paire d’épiceries, encerclez celle que vous préférez :
Kroger et First National
First National et A&P
A&P et Kroger
3. Que pouvez-vous dire des prix chez Vel-Mart :
Ils sont plus élevés que Sears.
Comme chez Sears
Inférieur à Sears.
B. Échelle d'intervalle
1. Veuillez évaluer chaque marque de produit en termes de qualité :
2. Veuillez indiquer votre niveau d'accord avec les énoncés suivants en encerclant l'un des chiffres :
d.Échelle de relation
1. Veuillez indiquer votre âge_________ ans
2. Indiquez approximativement combien de fois au cours du dernier mois vous avez effectué des achats dans un magasin de garde dans l'intervalle de temps de 20 à 23 heures.
0 1 2 3 4 5 un autre nombre de fois _______
3. Quelle est la probabilité que vous demandiez l’aide d’un avocat pour rédiger un testament ?
______________ pour cent
L'échelle d'ordre vous permet de classer les répondants ou leurs réponses. Elle possède les propriétés d’une échelle de dénomination combinée à une relation d’ordre. En d’autres termes, si chaque paire de catégories de l’échelle de dénomination est ordonnée les unes par rapport aux autres, alors une échelle ordinale sera obtenue. Pour que les notes de l'échelle diffèrent des nombres au sens ordinaire, elles sont appelées rangs au niveau ordinal. Par exemple, la fréquence d'achat d'un certain produit (une fois par semaine, une fois par mois ou plus souvent). Cependant, une telle échelle n'indique que la différence relative entre les objets mesurés.
Souvent, la prétendue distinction claire entre les évaluations n'est pas respectée et les personnes interrogées ne peuvent pas choisir sans ambiguïté une réponse ou une autre, c'est-à-dire : certaines gradations de réponses adjacentes se chevauchent. Une telle échelle est dite semi-ordonnée ; il se situe entre les échelles des noms et de l'ordre.
L'échelle d'intervalle présente également la caractéristique de la distance entre les gradations individuelles de l'échelle, mesurée à l'aide d'une unité de mesure spécifique, c'est-à-dire que des informations quantitatives sont utilisées. Sur cette échelle, les différences entre les différentes gradations de l'échelle n'ont plus de sens. Dans ce cas, vous pouvez décider s’ils sont égaux ou non, et s’ils ne sont pas égaux, lequel des deux est le plus grand. Des valeurs d'échelle des signes peuvent être ajoutées. On suppose généralement que l’échelle est uniforme (même si cette hypothèse doit être justifiée). Par exemple, si les commis de magasin sont évalués sur une échelle allant de extrêmement amical, très amical, plutôt amical, plutôt hostile, très, hostile, extrêmement hostile, alors on suppose généralement que les distances entre les différentes gradations sont les mêmes (chaque valeur de l'autre diffère d'un point - voir tableau 2).
L'échelle des ratios est la seule à avoir un point zéro, ce qui permet de faire des comparaisons quantitatives entre les résultats obtenus. Cet ajout permet de parler du rapport (proportion) a : b pour les valeurs d'échelle a et b. Par exemple, un répondant peut être 2,5 fois plus âgé, dépenser trois fois plus d’argent et prendre l’avion deux fois plus souvent qu’un autre répondant (tableau 2).
L'échelle de mesure choisie détermine la nature des informations dont disposera le chercheur lors de l'étude d'un objet. Mais il faut plutôt dire que le choix de l'échelle de mesure est déterminé par la nature de la relation entre les objets, la disponibilité des informations et les objectifs de l'étude. Si, par exemple, nous voulons classer des marques de produits, nous n’avons généralement pas besoin de déterminer dans quelle mesure une marque est meilleure qu’une autre. Il n’est donc pas nécessaire d’utiliser des échelles quantitatives (intervalles ou ratios) pour de telles mesures.
De plus, le type d'échelle détermine quel type d'analyse statistique peut ou non être utilisé.Lors de l'utilisation d'une échelle de dénomination, il est possible de trouver les fréquences de distribution, l'évolution moyenne de la fréquence modale, de calculer les coefficients d'interdépendance entre deux ou plusieurs séries de propriétés et utiliser des critères non paramétriques pour tester les hypothèses.
Parmi les indicateurs statistiques au niveau ordinal, des indicateurs de tendance centrale sont utilisés - médiane, quartiles, etc. Pour identifier l'interdépendance de deux caractéristiques, les coefficients de corrélation de rang de Spearman et Kendal sont utilisés.
Une grande variété d'actions peuvent être effectuées sur des nombres appartenant à l'échelle d'intervalle. L'échelle peut être compressée ou étendue un certain nombre de fois. Par exemple, si l'échelle a des divisions de 0 à 100, alors en divisant tous les nombres par 100, nous obtenons une échelle avec des valeurs de 0 à 1. Vous pouvez décaler toute l'échelle pour qu'elle soit composée de nombres de -50 à +50.
En plus des opérations algébriques évoquées ci-dessus, les échelles d'intervalles permettent toutes les opérations statistiques inhérentes au niveau ordinal ; Il est également possible de calculer la moyenne arithmétique, la variance, etc. Au lieu des coefficients de corrélation de rang, le coefficient de corrélation par paire de Pearson est calculé. Un coefficient de corrélation multiple peut également être calculé.
Toutes les opérations de calcul ci-dessus sont également applicables à l'échelle de ratio.
Il faut garder à l’esprit que les résultats obtenus peuvent toujours être traduits à une échelle plus simple, mais jamais l’inverse. Par exemple, les gradations « Fortement en désaccord » et « Plutôt en désaccord » (échelle d'intervalle) peuvent facilement être transférées à la catégorie « en désaccord » de l'échelle de dénomination.
Utiliser des échelles de mesure
Dans le cas le plus simple, une évaluation d'une caractéristique mesurée par un certain individu est effectuée en sélectionnant, en règle générale, une réponse parmi une série de réponses proposées ou en sélectionnant un score numérique parmi un certain ensemble de nombres.
Pour évaluer la qualité mesurée, on utilise parfois des échelles graphiques, divisées en parties égales et munies de symboles verbaux ou numériques. Il est demandé au répondant de faire une note sur l'échelle en fonction de son appréciation de cette qualité.
Comme indiqué ci-dessus, le classement des objets est une autre technique de mesure couramment utilisée. Lors du classement, on évalue la qualité mesurable d'un ensemble d'objets en les classant selon le degré d'expression de cette caractéristique. En règle générale, la première place correspond au niveau le plus élevé. Chaque objet se voit attribuer un score égal à sa place dans cette série classée.
L'avantage du classement en tant que méthode de mesure subjective réside dans la simplicité des procédures, qui ne nécessitent aucune formation d'experts à forte intensité de main-d'œuvre. Cependant, il est quasiment impossible d’organiser un grand nombre d’objets. Comme le montre l'expérience, lorsque le nombre d'objets est supérieur à 15-20, les experts ont du mal à établir des classements. Cela s'explique par le fait que dans le processus de classement, l'expert doit établir la relation entre tous les objets, en les considérant comme un seul ensemble. À mesure que le nombre d'objets augmente, le nombre de connexions entre eux augmente proportionnellement au carré du nombre. d'objets. Le stockage en mémoire et l'analyse d'un large éventail de relations entre objets sont limités par les capacités psychologiques d'une personne. Par conséquent, lors du classement d’un grand nombre d’objets, les experts peuvent commettre des erreurs importantes. Dans ce cas, la méthode de comparaison par paires peut être utilisée.
La comparaison par paires est la procédure consistant à établir une préférence pour les objets lors de la comparaison de toutes les paires possibles et à ordonner davantage les objets en fonction des résultats de la comparaison. Contrairement au classement, dans lequel l'ordre de tous les objets est effectué, la comparaison par paires d'objets est une méthode plus simple. tâche. La comparaison par paires, comme le classement, est une mesure sur une échelle ordinale.
Cependant, cette approche est plus complexe et est plus susceptible d’être utilisée lors d’enquêtes auprès d’experts plutôt que de répondants de masse.
Supposons que l'attitude envers des valeurs de produits telles que « bénéfice », « design », « qualité », « période de garantie », « service après-vente », « prix », etc. soit clarifiée. classement simple (détermination des poids des caractéristiques ) il est difficile ou assez important de déterminer avec précision les poids d'échelle des caractéristiques étudiées, de sorte que leur détermination directe par des experts ne peut pas être effectuée. Par simplicité, désignons ces valeurs par les symboles A1, A2, A3,..., Ak.
Les répondants (experts) comparent ces caractéristiques par paires afin de déterminer la plus importante (significative) d'entre elles dans chaque paire.
À partir des symboles, nous formons toutes sortes de paires : (A1A2), (A1A3), etc. Le nombre total de ces combinaisons par paires sera x (k – 1)/2, où k est le nombre de caractéristiques évaluées. Ensuite, les objets sont classés en fonction des résultats de leur comparaison par paires.
La méthode des comparaisons appariées peut également être utilisée pour déterminer les poids relatifs des objectifs, des critères, des facteurs, etc., effectués lors de la réalisation de diverses études marketing.
Dans de nombreux cas, lors de l'élaboration de questionnaires, il n'est pas conseillé de développer des échelles de mesure à partir de zéro. Il est préférable d’utiliser les types de balances standard utilisés dans le secteur des études de marché. Ces échelles comprennent : l’échelle de Likert modifiée, l’échelle de style de vie et l’échelle différentielle sémantique.
Sur la base d'une échelle de Likert modifiée (échelle d'intervalle), adaptée aux objectifs de l'étude marketing menée, le degré d'accord ou de désaccord des répondants avec certaines affirmations est étudié. Cette échelle est de nature symétrique et mesure l’intensité des sentiments des répondants.
Dans le tableau La figure 3 montre un questionnaire basé sur une échelle de Likert. Ce questionnaire peut être utilisé pour réaliser des enquêtes téléphoniques auprès des consommateurs. L'enquêteur lit les questions et demande aux répondants d'indiquer leur degré d'accord avec chaque affirmation.
Tableau 3
Questionnaire pour identifier les avis des consommateurs concernant un produit d'une certaine marque
Il existe différentes options pour modifier l'échelle de Likert, par exemple en introduisant un nombre différent de gradations (7 à 9).
L'échelle d'étude du style de vie est un domaine d'application particulier de l'échelle de Likert modifiée et est conçue pour étudier le système de valeurs, les qualités personnelles, les intérêts, les opinions concernant le travail, les loisirs et les achats de diverses personnes. Ces informations vous permettent de prendre des décisions marketing efficaces. Un exemple de questionnaire pour étudier le style de vie est donné dans le tableau. 4.
Tableau 4
Enquête sur le style de vie
Veuillez encercler le chiffre qui représente le mieux votre niveau d’accord ou de désaccord avec chaque énoncé.
| Déclaration | Tout à fait d'accord | Je suis d'accord dans une certaine mesure | je suis neutre | Dans une certaine mesure, je ne suis pas d'accord | Fortement en désaccord |
| 1. J'achète beaucoup d'articles spéciaux | 1 | 2 | 3 | 4 | 5 |
| 2. J’ai généralement une ou plusieurs dernières tendances en matière de mode. | 1 | 2 | 3 | 4 | 5 |
| 3. La chose la plus importante pour moi, ce sont mes enfants. | 1 | 2 | 3 | 4 | 5 |
| 4. Je garde généralement ma maison en bon état. | 1 | 2 | 3 | 4 | 5 |
| 5. Je préfère passer la soirée à la maison plutôt que d'aller à une fête | 1 | 2 | 3 | 4 | 5 |
| 6. J'aime regarder ou écouter les retransmissions de matchs de football. | 1 | 2 | 3 | 4 | 5 |
| 7. J’influence souvent les demandes de mes amis. | 1 | 2 | 3 | 4 | 5 |
| 8. L’année prochaine, j’aurai plus d’argent pour faire du shopping. | 1 | 2 | 3 | 4 | 5 |
L'échelle différentielle sémantique contient une série de définitions bipolaires qui caractérisent diverses propriétés de l'objet étudié. Étant donné que de nombreux stimuli marketing reposent sur des associations mentales et des relations qui ne sont pas explicitement exprimées, ce type d'échelle est souvent utilisé pour déterminer l'image d'une marque, d'un magasin, etc. Les résultats de l'étude des opinions des consommateurs concernant deux restaurants (#1 et #2) sur la base d'une échelle différentielle sémantique sont présentés dans le tableau. 5.
Tableau 5
Bilan comparatif de deux restaurants
Désignations : ligne continue – notes du restaurant n°1, ligne pointillée – restaurant n°2.
Dans le tableau En particulier, toutes les notes positives ou négatives ne sont pas situées d'un seul côté, mais sont mélangées de manière aléatoire. Ceci est fait afin d’éviter « l’effet de halo ». Cela réside dans le fait que si le premier objet évalué a des premières notes (côté gauche du questionnaire) plus élevées que le deuxième objet, alors le répondant aura tendance à continuer à donner des notes à gauche.
L'un des avantages de cette méthode est que si les gradations individuelles de l'échelle reçoivent des numéros : 1, 2, 3, etc., et que les données des différents répondants sont saisies dans l'ordinateur, les résultats finaux peuvent être obtenus sous forme graphique. (Tableau 5 ).
Lors de l'utilisation des échelles ci-dessus, la question se pose de l'opportunité d'utiliser un point neutre. Tout dépend si les répondants ont une opinion neutre ou non. Il n'est pas possible de donner une recommandation sans ambiguïté sur cette question.
La même chose peut être dite quant à savoir s’il faut construire une échelle symétrique ou asymétrique.
Il existe une grande variété d'options d'échelle construites sur la base des principes énoncés. Le choix final est généralement effectué sur la base de tests du niveau de fiabilité et de précision des mesures effectuées à l'aide de différentes options d'échelle.
Fiabilité et validité de la mesure des informations marketing
Les méthodes de construction des échelles décrites ci-dessus ne fournissent pas une image complète des propriétés des estimations résultantes. Des procédures supplémentaires sont nécessaires pour identifier les erreurs inhérentes à ces estimations. Appelons cela le problème de la fiabilité des mesures. Ce problème est résolu en identifiant la validité, la robustesse et la validité des mesures.
Lors de l'étude de l'exactitude, l'acceptabilité générale d'une méthode de mesure donnée (échelle ou système d'échelles) est établie. Le concept d'exactitude est directement lié à la possibilité de prendre en compte divers types d'erreurs systématiques résultant de la mesure. Les erreurs systématiques ont un certain caractère stable : soit elles sont constantes, soit elles varient selon une certaine loi.
La stabilité caractérise le degré d'accord entre les résultats de mesure lors d'applications répétées de la procédure de mesure et est décrite par l'ampleur de l'erreur aléatoire. Elle est déterminée par la cohérence de l’approche du répondant pour répondre à des questions identiques ou similaires.
Par exemple, vous êtes l'un des répondants répondant aux questions du questionnaire du tableau. 5 concernant les activités d'un restaurant. En raison de la lenteur du service dans ce restaurant, vous êtes arrivé en retard à un rendez-vous d'affaires et vous avez donc attribué la note la plus basse pour cet indicateur. Une semaine plus tard, ils vous ont appelé et vous ont demandé de confirmer que vous aviez effectivement participé à l'enquête. On vous a ensuite demandé de répondre à une série de questions de suivi par téléphone, notamment une question sur la rapidité du service sur une échelle de 1 à 7, 7 étant le service le plus rapide. Vous avez attribué un 2, démontrant un haut niveau d'identité des notes et donc la stabilité de vos notes.
La question la plus difficile de la fiabilité des mesures est celle de leur validité. La validité est associée à la preuve qu'une propriété spécifiée très spécifique d'un objet a été mesurée, et non une autre, plus ou moins similaire à celle-ci.
Lors de l'établissement de la fiabilité, il convient de garder à l'esprit que trois composants sont impliqués dans le processus de mesure : l'objet de mesure, les moyens de mesure à l'aide desquels les propriétés de l'objet sont mappées au système numérique et le sujet (enquêteur ) en effectuant la mesure. Les conditions préalables à une mesure fiable résident dans chaque composant individuel.
Tout d'abord, lorsqu'une personne agit comme objet de mesure, elle peut avoir un degré d'incertitude important par rapport à la propriété mesurée. Ainsi, souvent, le répondant n'a pas de hiérarchie claire des valeurs de la vie et, par conséquent, il est impossible d'obtenir des données absolument précises caractérisant l'importance de certains phénomènes pour lui. Il peut être peu motivé, ce qui l'amène à répondre aux questions de manière inattentive. Cependant, ce n'est qu'en dernier recours qu'il faut chercher la raison du manque de fiabilité des estimations chez le répondant lui-même.
Par contre, il se peut que la méthode d’obtention de l’évaluation ne soit pas en mesure de fournir les valeurs les plus précises pour la propriété mesurée. Par exemple, un répondant dispose d'une hiérarchie détaillée de valeurs, et pour obtenir des informations, une échelle avec des variations de réponses uniquement « très important » et « pas du tout important » est utilisée. En règle générale, toutes les valeurs de l'ensemble donné sont marquées des réponses « très important », bien qu'en réalité le répondant ait un plus grand nombre de niveaux d'importance.
Enfin, en présence d'une grande précision des deux premières composantes de la mesure, le sujet effectuant la mesure commet des erreurs grossières ; les instructions pour le questionnaire ne sont pas claires ; L’enquêteur formule à chaque fois la même question différemment, en utilisant une terminologie différente.
Par exemple, lors d'un entretien au cours duquel le système de valeurs du répondant devrait être révélé, l'intervieweur n'a pas pu transmettre au répondant l'essence de l'enquête, n'a pas pu adopter une attitude amicale envers la recherche, etc.
Chaque composante du processus de mesure peut être une source d'erreur liée soit à la robustesse, à l'exactitude ou à la validité. Cependant, en règle générale, le chercheur n'est pas en mesure de séparer ces erreurs selon leurs sources et étudie donc les erreurs de stabilité, d'exactitude et de validité de l'ensemble du complexe de mesure dans son intégralité. Dans le même temps, l'exactitude (comme l'absence d'erreurs systématiques) et la stabilité des informations sont des conditions élémentaires de fiabilité. La présence d'une erreur significative à cet égard annule déjà le contrôle de validité des données de mesure.
Contrairement à l'exactitude et à la stabilité, qui peuvent être mesurées de manière assez stricte et exprimées sous la forme d'un indicateur numérique, les critères de validité sont déterminés soit sur la base d'un raisonnement logique, soit sur la base d'indicateurs indirects. En règle générale, une comparaison des données d'une technique avec les données d'autres techniques ou études est utilisée.
Avant de commencer à étudier les éléments de fiabilité tels que la stabilité et la validité, vous devez vous assurer que l'outil de mesure choisi est correct.
Il est possible que les étapes ultérieures s'avèrent inutiles s'il s'avère au tout début que l'instrument est totalement incapable de différencier la population étudiée au niveau requis, en d'autres termes, s'il s'avère qu'une partie de la L'échelle ou telle ou telle gradation de l'échelle ou de la question n'est pas systématiquement utilisée. Et enfin, il est possible que la caractéristique originale n'ait pas de capacité de différenciation par rapport à l'objet de mesure. Tout d'abord, il est nécessaire d'éliminer ou de réduire ces défauts de l'échelle et ensuite seulement de l'utiliser dans l'étude.
Les inconvénients de l'échelle utilisée incluent tout d'abord le manque de dispersion des réponses entre les valeurs de l'échelle. Si les réponses se résument à un seul point, cela indique l'inadéquation totale de l'instrument de mesure - la balance. Cette situation peut survenir soit en raison d'une pression « normative » vers l'opinion généralement acceptée, soit en raison du fait que les gradations (valeurs) de l'échelle ne sont pas liées à la répartition d'une propriété donnée dans les objets en question (non pertinent).
Par exemple, si tous les répondants sont d'accord avec l'affirmation « c'est bien quand un outil de construction est universel », il n'y a pas une seule réponse « en désaccord », alors une telle échelle n'aidera pas à différencier les attitudes des répondants envers les différents types d'outils de construction.
Utiliser une partie de la balance. Très souvent, on découvre que seule une partie de l'échelle, un de ses pôles avec une zone adjacente plus ou moins étendue, fonctionne pratiquement.
Ainsi, si les répondants se voient proposer une échelle d'évaluation comportant des pôles positifs et négatifs, en particulier de +3 à – 3, alors lors de l'évaluation d'une situation manifestement positive, les répondants n'utilisent pas d'évaluations négatives, mais différencient leurs opinions uniquement à l'aide de les positifs. Afin de calculer la valeur de l'erreur de mesure relative, le chercheur doit savoir avec certitude quelle métrique le répondant utilise - les sept gradations de l'échelle ou seulement quatre positives. Ainsi, une erreur de mesure de 1 point ne dit pas grand-chose si l’on ne sait pas quelle est la variation réelle des opinions.
Pour les questions qui ont des gradations qualitatives de réponses, une exigence similaire peut être appliquée à chaque point de l'échelle : chacun d'eux doit recevoir au moins 5 % des réponses, sinon nous considérons ce point de l'échelle comme invalide. L'exigence d'un niveau de remplissage de 5 % pour chaque gradation de l'échelle ne doit pas être considérée comme strictement obligatoire ; En fonction des objectifs de l’étude, des valeurs plus ou moins grandes de ces niveaux pourront être proposées.
Utilisation inégale des éléments individuels de la balance. Il arrive qu'une certaine valeur d'une caractéristique échappe systématiquement au champ de vision des répondants, bien que les gradations voisines caractérisant les degrés d'expression inférieurs et supérieurs de la caractéristique aient un contenu important.
Une situation similaire est observée dans le cas où le répondant se voit proposer une échelle trop granulaire : étant incapable d'opérer avec toutes les gradations de l'échelle, le répondant n'en sélectionne que quelques-unes de base. Par exemple, les personnes interrogées considèrent souvent une échelle de dix points comme une modification d’une échelle de cinq points, en supposant que « dix » correspond à « cinq », « huit » à « quatre », « cinq » à « trois », etc. Dans le même temps, les notations de base sont utilisées beaucoup plus souvent que les autres.
Pour identifier ces anomalies de répartition uniforme sur l'échelle, la règle suivante peut être proposée : pour une probabilité de confiance suffisamment grande (1-a > 0,99) et donc dans des limites suffisamment larges, le remplissage de chaque valeur ne doit pas différer significativement de la moyenne des obturations voisines. A quoi sert le test du Chi carré ?
Définition des erreurs. Au cours du processus de mesure, des erreurs grossières se produisent parfois, dont la cause peut être un enregistrement incorrect des données source, de mauvais calculs, une utilisation non qualifiée des instruments de mesure, etc. Cela se révèle dans le fait que dans la série de mesures, il existe des données qui diffèrent nettement de la totalité de toutes les autres valeurs. Pour déterminer si ces valeurs doivent être considérées comme des erreurs grossières, une limite critique est fixée de sorte que la probabilité que les valeurs extrêmes la dépassent soit suffisamment petite pour correspondre à un certain niveau de signification a. Cette règle repose sur le fait que l'apparition de valeurs trop élevées dans un échantillon, bien que possible en raison de la variabilité naturelle des valeurs, est peu probable.
S'il s'avère que certaines valeurs extrêmes de la population lui appartiennent avec une très faible probabilité, alors ces valeurs sont reconnues comme des erreurs grossières et sont exclues d'un examen plus approfondi. Il est particulièrement important d'identifier les erreurs grossières pour les petits échantillons : sans être exclus de l'analyse, ils faussent significativement les paramètres des échantillons. À cette fin, des critères statistiques spéciaux sont utilisés pour déterminer les erreurs grossières.
Ainsi, la capacité différenciatrice d'une échelle, comme première caractéristique essentielle de sa fiabilité, suppose : d'assurer une diffusion suffisante des données ; identifier l’utilisation réelle par le répondant de la longueur d’échelle proposée ; analyse des valeurs individuelles « aberrantes » ; éliminer les erreurs grossières. Une fois établie l’acceptabilité relative des échelles utilisées dans ces aspects, il convient de procéder à l’identification de la stabilité des mesures sur cette échelle.
Stabilité des mesures. Il existe plusieurs méthodes pour évaluer la stabilité des mesures : tests répétés ; inclusion de questions équivalentes dans le questionnaire et division de l'échantillon en deux parties.
Souvent, à la fin de l’enquête, les enquêteurs la répètent partiellement en disant : « Lorsque nous aurons terminé notre travail, reprenons brièvement les questions du questionnaire afin que je puisse vérifier si j’ai tout noté correctement à partir de vos réponses. » Bien entendu, nous ne parlons pas de répéter toutes les questions, mais seulement les plus critiques. Il ne faut pas oublier que si l'intervalle de temps entre le test et le nouveau test est trop court, le répondant peut alors simplement se souvenir des réponses initiales. Si l’intervalle est trop long, de réels changements peuvent survenir.
Inclure des questions équivalentes dans un questionnaire implique d’utiliser des questions sur le même problème, mais formulées différemment, dans un même questionnaire. Le répondant doit les percevoir comme des questions différentes. Le principal danger de cette méthode réside dans le degré d’équivalence des questions ; si cet objectif n’est pas atteint, le répondant répond à différentes questions.
La division de l'échantillon en deux parties repose sur la comparaison des réponses aux questions de deux groupes de répondants. On suppose que les deux groupes sont de composition identique et que les scores de réponse moyens des deux groupes sont très similaires. Toutes les comparaisons sont effectuées uniquement sur une base de groupe, de sorte que des comparaisons au sein d'un groupe ne peuvent pas être effectuées. Par exemple, les étudiants ont été interrogés à l’aide d’une échelle de Likert modifiée à cinq points concernant leur future carrière. Le questionnaire comprenait la déclaration : « Je crois qu’une brillante carrière m’attend. » Les réponses ont été résumées de « Fortement en désaccord » (1 point) à « Tout à fait d’accord » (5 points). L'échantillon total de répondants a ensuite été divisé en deux groupes et les scores moyens de ces groupes ont été calculés. Le score moyen était le même pour chaque groupe et équivalait à 3 points. Ces résultats permettent de considérer la mesure comme fiable. Lorsque nous avons analysé plus attentivement les réponses des groupes, il s'est avéré que dans un groupe, tous les étudiants ont répondu « à la fois d'accord et en désaccord », tandis que dans l'autre, 50 % ont répondu « tout à fait en désaccord » et les 50 % restants ont répondu « tout à fait d'accord ». Comme vous pouvez le constater, une analyse plus approfondie a montré que les réponses ne sont pas identiques.
En raison de cet inconvénient, cette méthode d'évaluation de la stabilité des mesures est la moins populaire.
On ne peut parler de la grande fiabilité d'une balance que si des mesures répétées l'utilisant sur les mêmes objets donnent des résultats similaires. Si la stabilité est vérifiée sur le même échantillon, il suffit souvent d'effectuer deux mesures consécutives avec un certain intervalle de temps - de telle sorte que cet intervalle ne soit pas trop long pour qu'une modification de l'objet lui-même soit affectée, mais pas non plus trop petit pour que que le répondant peut se souvenir de mémoire de « remonter » les données de la deuxième mesure vers la précédente (c'est-à-dire que sa durée dépend de l'objet d'étude et varie de deux à trois semaines).
Il existe différents indicateurs pour évaluer la stabilité des mesures. Parmi eux, le plus couramment utilisé est l’erreur quadratique moyenne.
Jusqu'à présent, nous parlions d'erreurs absolues dont la taille était exprimée dans les mêmes unités que la valeur mesurée elle-même. Cela ne nous permet pas de comparer les erreurs de mesure de différents caractères à différentes échelles. Par conséquent, en plus des indicateurs absolus, des indicateurs relatifs des erreurs de mesure sont nécessaires.
En tant qu'indicateur permettant de mettre l'erreur absolue sous forme relative, vous pouvez utiliser l'erreur maximale possible dans l'échelle considérée, dans laquelle sont divisées les erreurs de mesure moyennes arithmétiques.
Cependant, cet indicateur « fonctionne souvent mal » du fait que l'échelle n'est pas utilisée sur toute sa longueur. Par conséquent, les erreurs relatives calculées à partir de la partie de l’échelle réellement utilisée sont plus indicatives.
Pour augmenter la stabilité de la mesure, il est nécessaire de connaître les capacités discriminantes des items de l'échelle utilisée, ce qui suppose que les répondants notent clairement les valeurs individuelles : chaque évaluation doit être strictement séparée de la voisine. En pratique, cela signifie que dans les échantillons successifs, les répondants répètent clairement leurs évaluations. Par conséquent, une petite erreur devrait correspondre à une grande visibilité des divisions d’échelle.
Mais même avec un petit nombre de gradations, c'est-à-dire avec un faible niveau de capacités discriminantes de l'échelle, la stabilité peut être faible, et la granularité de l'échelle doit alors être augmentée. Cela se produit lorsque des réponses catégoriques « oui » et « non » sont imposées au répondant, mais qu'il préférerait des évaluations moins strictes. Et c'est pourquoi il choisit lors de tests répétés tantôt « oui », tantôt « non »,
Si un mélange de gradations est détecté, l'une des deux méthodes d'agrandissement de l'échelle est utilisée.
Première façon. Dans la version finale, la granularité de l'échelle est réduite (par exemple, d'une échelle de 7 intervalles on passe à une échelle de 3 intervalles).
Deuxième façon. Pour la présentation au répondant, la granularité précédente de l'échelle est conservée et ce n'est que lors du traitement que les points correspondants sont agrandis.
La deuxième méthode semble préférable, car, en règle générale, une plus grande granularité de l'échelle incite le répondant à une réaction plus active. Lors du traitement des données, les informations doivent être recodées conformément à l'analyse de la capacité discriminante de l'échelle d'origine.
L'analyse de la stabilité des questions individuelles sur l'échelle permet : a) d'identifier les questions mal formulées et leur incompréhension par les différents répondants ; b) clarifier l'interprétation de l'échelle proposée pour évaluer un phénomène particulier et identifier une option plus optimale pour le fractionnement de la valeur de l'échelle.
Validité de la mesure. La vérification de la validité de l'échelle n'est entreprise qu'après avoir établi une précision et une stabilité suffisantes de la mesure des données originales.
La validité des données de mesure est la preuve de l'accord entre ce qui est mesuré et ce qui était censé être mesuré. Certains chercheurs préfèrent partir de la validité dite disponible, c'est-à-dire la validité en termes de procédure utilisée. Par exemple, ils pensent que la satisfaction à l'égard d'un produit est la propriété contenue dans les réponses à la question : « Êtes-vous satisfait du produit ? Dans le cadre d’une recherche marketing sérieuse, une telle approche purement empirique peut s’avérer inacceptable.
Arrêtons-nous sur les approches formelles possibles pour déterminer le niveau de validité de la méthodologie. Ils peuvent être divisés en trois groupes : 1) construction d'une typologie conforme aux objectifs de l'étude basée sur plusieurs caractéristiques ; 2) utilisation de données parallèles ; 3) procédures judiciaires.
La première option ne peut pas être considérée comme une méthode complètement formelle - il s'agit simplement d'une schématisation d'un raisonnement logique, du début d'une procédure de justification, qui peut y être complétée ou soutenue par des moyens plus puissants.
La deuxième option nécessite l’utilisation d’au moins deux sources pour identifier le même bien. La validité est déterminée par le degré de cohérence des données pertinentes.
Dans ce dernier cas, nous nous appuyons sur la compétence des juges à qui il est demandé de déterminer si nous mesurons la propriété dont nous avons besoin ou autre chose.
La typologie construite consiste en l'utilisation de questions de contrôle qui, avec les principales, donnent une meilleure approximation du contenu du bien étudié, révélant ses différents aspects.
Par exemple, vous pouvez déterminer votre satisfaction à l'égard du modèle de voiture que vous utilisez avec une question simple : « Êtes-vous satisfait de votre modèle de voiture actuel ? » En le combinant avec deux autres indirects : « Voulez-vous passer à un autre modèle ? » et "Recommandez-vous à votre ami d'acheter ce modèle de voiture ?" permet une différenciation plus fiable des répondants. Ensuite, une typologie est réalisée en cinq groupes ordonnés du plus satisfait de la voiture au moins satisfait.
L'utilisation de données parallèles implique le développement de deux méthodes égales pour mesurer une caractéristique donnée. Cela permet d'établir la validité des méthodes les unes par rapport aux autres, c'est-à-dire d'augmenter la validité globale en comparant deux résultats indépendants.
Voyons différentes manières d'utiliser cette approche, et tout d'abord des échelles équivalentes. Des échantillons équivalents de caractéristiques sont possibles pour décrire la mesure du comportement, de l'attitude, de l'orientation des valeurs, c'est-à-dire une sorte d'installation. Ces échantillons forment des échelles parallèles, offrant une fiabilité concurrente.
Nous considérons chaque échelle comme un moyen de mesurer une certaine propriété et, en fonction du nombre d'échelles parallèles, nous disposons d'un certain nombre de méthodes de mesure. Le répondant donne des réponses simultanément sur toutes les échelles parallèles.
Lors du traitement de ce type de données, deux points doivent être clarifiés : 1) la cohérence des items sur une échelle distincte ; 2) cohérence des évaluations à différentes échelles.
Le premier problème vient du fait que les modèles de réponse ne présentent pas une image parfaite ; les réponses se contredisent souvent. Par conséquent, la question se pose de savoir quelle est la véritable valeur de l’évaluation du répondant sur cette échelle.
Le deuxième problème concerne directement la cartographie de données parallèles.
Prenons l'exemple d'une tentative infructueuse visant à améliorer la fiabilité de la mesure du trait « satisfaction à l'égard d'une voiture » à l'aide de trois échelles ordinales parallèles. En voici deux :
Quinze jugements (dans l'ordre indiqué à gauche, au début de chaque ligne) sont présentés au défendeur sous forme d'une liste générale, et il doit exprimer son accord ou son désaccord avec chacun d'eux. Chaque jugement se voit attribuer une note correspondant à son rang sur l'échelle de cinq points spécifiée (à droite). (Par exemple, l’accord avec le jugement 4 donne une note de « 1 », l’accord avec le jugement 11 – une note de « 5 », etc.)
La méthode de présentation des jugements sous forme de liste, envisagée ici, permet d'analyser la cohérence des éléments de l'échelle. Lorsqu'on utilise des échelles de noms ordonnées, on suppose généralement que les éléments qui composent l'échelle s'excluent mutuellement et que le répondant trouvera facilement celui qui lui convient.
L'étude des répartitions des réponses montre que les répondants expriment leur accord avec des jugements contradictoires (du point de vue de l'hypothèse initiale). Par exemple, sur l'échelle « B », 42 personnes sur 100 étaient simultanément d'accord avec les jugements 13 et 12, c'est-à-dire avec deux jugements opposés.
La présence de jugements contradictoires dans les réponses sur l'échelle B conduit à considérer l'échelle comme inacceptable.
Cette approche pour augmenter la fiabilité d’une balance est très complexe. Par conséquent, cela ne peut être recommandé que lors du développement de tests critiques ou de techniques destinées à une utilisation de masse ou à des études par panel.
Il est possible de tester une méthode sur plusieurs répondants. Si la méthode est fiable, alors les différents répondants donneront des informations cohérentes, mais si leurs résultats sont peu cohérents, alors soit les mesures ne sont pas fiables, soit les résultats des répondants individuels ne peuvent pas être considérés comme équivalents. Dans ce dernier cas, il est nécessaire de déterminer si un groupe de résultats peut être considéré comme plus fiable. La solution à ce problème est d'autant plus importante si l'on suppose qu'il est également permis d'obtenir des informations par n'importe laquelle des méthodes considérées.
L’utilisation de méthodes parallèles pour mesurer la même propriété se heurte à un certain nombre de difficultés.
Premièrement, il n’est pas clair dans quelle mesure les deux méthodes mesurent la même qualité de l’objet et, en règle générale, il n’existe aucun critère formel pour tester une telle hypothèse. Par conséquent, il est nécessaire de recourir à une justification substantielle (logique-théorique) d'une méthode particulière.
Deuxièmement, si des procédures parallèles sont trouvées pour mesurer une propriété commune (les données ne diffèrent pas de manière significative), la question demeure quant à la justification théorique de l'utilisation de ces procédures.
Il faut admettre que le principe même du recours à des procédures parallèles s'avère être non pas un principe formel, mais plutôt un principe de fond dont l'application est très difficile à justifier théoriquement.
L'une des approches les plus répandues pour établir la validité consiste à faire appel à ce qu'on appelle des juges, des experts. Les chercheurs demandent à un groupe spécifique de personnes d’agir en tant qu’individus compétents. On leur propose un ensemble de caractéristiques destinées à mesurer l'objet étudié, et il leur est demandé d'évaluer l'exactitude de l'attribution de chacune des caractéristiques à cet objet. Le traitement conjoint des avis des juges permettra d'attribuer des poids aux caractéristiques ou, ce qui revient au même, des notes d'échelle dans la mesure de l'objet étudié. Un ensemble de caractéristiques peut être une liste de jugements individuels, de caractéristiques d'un objet, etc.
Les procédures de jugement sont variées. Ils peuvent être fondés sur des méthodes de comparaisons appariées, de classement, d'intervalles séquentiels, etc.
La question de savoir qui doit être considéré comme juge est assez controversée. Les juges sélectionnés comme représentants de la population étudiée doivent, d’une manière ou d’une autre, représenter son micromodèle : selon les appréciations des juges, le chercheur détermine dans quelle mesure certains points de la procédure d’enquête seront interprétés par les répondants.
Cependant, lors de la sélection des juges, une question difficile se pose : quelle est l'influence des propres attitudes des juges sur leurs appréciations, car ces attitudes peuvent différer sensiblement des attitudes des sujets par rapport au même objet.
D'une manière générale, la solution au problème consiste à : a) analyser soigneusement la composition des juges du point de vue de l'adéquation de leur expérience de vie et des signes de leur statut social aux indicateurs correspondants de la population interrogée ; b) identifier l'effet des écarts individuels dans les notes des juges par rapport à la distribution globale des notes. Enfin, il est nécessaire d’évaluer non seulement la qualité, mais également la taille de l’échantillon de juges.
D'une part, ce nombre est déterminé par la cohérence : si la cohérence des avis des juges est suffisamment élevée et, par conséquent, l'erreur de mesure est faible, le nombre de juges peut être faible. Il est nécessaire de définir la valeur de l'erreur tolérée et, sur cette base, de calculer la taille d'échantillon requise.
Si une incertitude totale de l'objet est détectée, c'est-à-dire dans le cas où les avis des juges sont répartis uniformément dans toutes les catégories d'évaluation, aucune augmentation de la taille de l'échantillon de juges ne sauvera la situation et ne fera pas sortir l'objet du état d’incertitude.
Si l'objet est suffisamment incertain, un grand nombre de gradations ne fera qu'introduire une interférence supplémentaire dans le travail des juges et ne fournira pas d'informations plus précises. Il est nécessaire d'identifier la stabilité des opinions des juges à l'aide de tests répétés et, en conséquence, de réduire le nombre de gradations.
Le choix d'une méthode, d'une méthode ou d'une technique particulière pour vérifier la validité dépend de nombreuses circonstances.
Tout d'abord, il convient d'établir clairement si des écarts significatifs par rapport au programme de mesure prévu sont possibles. Si le programme de recherche fixe des limites strictes, non pas une, mais plusieurs méthodes doivent être utilisées pour vérifier la validité des données.
Deuxièmement, il faut garder à l’esprit que les niveaux de robustesse et de validité des données sont étroitement liés. Les informations instables, du fait de leur manque de fiabilité selon ce critère, ne nécessitent pas une vérification de validité trop stricte. Une robustesse suffisante doit être assurée, puis des mesures appropriées doivent être prises pour clarifier les limites de l'interprétation des données (c'est-à-dire identifier le niveau de validité).
De nombreuses expériences visant à identifier le niveau de fiabilité permettent de conclure que dans le processus de développement des instruments de mesure, en termes de fiabilité, la séquence suivante des principales étapes de travail est conseillée :
a) Contrôle préliminaire de la validité des méthodes de mesure des données primaires au stade du test de la méthodologie. Il est ici vérifié dans quelle mesure les informations répondent essentiellement à leur objectif prévu et quelles sont les limites de l'interprétation ultérieure des données. À cette fin, de petits échantillons de 10 à 20 observations suffisent, suivis d’ajustements de la structure de la méthodologie.
b) La deuxième étape consiste à piloter la méthodologie et à vérifier minutieusement la stabilité des données initiales, notamment les indicateurs et échelles sélectionnés. À ce stade, il faut un échantillon qui représente un micromodèle de la population réelle des répondants.
c) Au cours d'une même voltige générale, toutes les opérations nécessaires liées à la vérification du niveau de validité sont effectuées. Les résultats de l'analyse des données pilotes conduisent à l'amélioration de la méthodologie, au raffinement de tous ses détails et, finalement, à l'obtention de la version finale de la méthodologie pour l'étude principale.
d) Au début de l'étude principale, il convient de vérifier la stabilité de la méthode utilisée afin de calculer des indicateurs précis de sa stabilité. La clarification ultérieure des limites de validité passe par l'ensemble de l'analyse des résultats de l'étude elle-même.
Quelle que soit la méthode d’évaluation de la fiabilité utilisée, le chercheur dispose de quatre étapes séquentielles pour améliorer la fiabilité des résultats de mesure.
Premièrement, lorsque la fiabilité des mesures est extrêmement faible, certaines questions sont simplement supprimées du questionnaire, en particulier lorsque le degré de fiabilité peut être déterminé au cours du processus d’élaboration du questionnaire.
Deuxièmement, le chercheur peut « réduire » les échelles et utiliser moins de gradations. Disons que l'échelle de Likert dans ce cas ne peut comprendre que les gradations suivantes : « d'accord », « pas d'accord », « je n'ai pas d'opinion ». Cela se fait généralement lorsque la première étape est terminée et lorsque l'examen a déjà été effectué.
Troisièmement, comme alternative à la deuxième étape ou comme approche menée après la deuxième étape, l'évaluation de la fiabilité est réalisée au cas par cas. Disons qu'une comparaison directe est faite des réponses des répondants lors de leurs tests initiaux et retestés ou avec une réponse équivalente. Les réponses des répondants peu fiables ne sont tout simplement pas prises en compte dans l’analyse finale. Évidemment, si vous utilisez cette approche sans évaluation objective de la fiabilité des répondants, alors en rejetant les réponses « indésirables », les résultats de la recherche peuvent être ajustés à ceux souhaités.
Enfin, après avoir utilisé les trois premières étapes, le niveau de fiabilité des mesures peut être évalué. Typiquement, la fiabilité des mesures est caractérisée par un coefficient variant de zéro à un, où l'on caractérise la fiabilité maximale.
On considère généralement que le niveau minimum acceptable de fiabilité se caractérise par des chiffres compris entre 0,65 et 0,70, surtout si les mesures ont été effectuées pour la première fois.
Il est évident qu'au cours du processus d'études marketing diverses et nombreuses menées par différentes entreprises, il y a eu une adaptation cohérente des échelles de mesure et des méthodes de leur mise en œuvre aux buts et objectifs d'études marketing spécifiques. Cela facilite la résolution des problèmes abordés dans cette section et le rend plutôt nécessaire lors de la réalisation d'une étude marketing originale.
La validité des mesures caractérise des aspects complètement différents de la fiabilité des mesures. Une mesure peut être fiable mais non valide. Cette dernière caractérise la précision des mesures par rapport à ce qui existe dans la réalité. Par exemple, on a interrogé un répondant sur son revenu annuel, qui est inférieur à 25 000 $. Réticent à donner le chiffre exact à l’intervieweur, le répondant a déclaré un revenu « supérieur à 100 000 $ ». Lors d'un nouveau test, il a de nouveau nommé ce chiffre, démontrant un haut niveau de fiabilité des mesures. Le mensonge n’est pas la seule raison du faible niveau de fiabilité des mesures. On peut aussi parler de mauvaise mémoire, de mauvaise connaissance de la réalité par le répondant, etc.
Considérons un autre exemple qui caractérise la différence entre fiabilité et validité des mesures. Même une montre inexacte affichera l’heure à une heure deux fois par jour, démontrant une grande fiabilité. Cependant, ils peuvent être très imprécis, c'est-à-dire L’affichage de l’heure ne sera pas fiable.
La principale direction pour vérifier la fiabilité des mesures est d'obtenir des informations provenant de diverses sources. Cela peut se faire de différentes façons. Ici, tout d'abord, il convient de noter ce qui suit.
Nous devons nous efforcer de formuler les questions de manière à ce que leur formulation contribue à obtenir des réponses fiables. D'autres questions liées les unes aux autres peuvent être incluses dans le questionnaire.
Par exemple, le questionnaire contient une question sur la mesure dans laquelle le répondant aime un certain produit alimentaire d'une certaine marque. Il est ensuite demandé quelle quantité de ce produit a été achetée par le répondant au cours du mois dernier. Cette question vise à vérifier la fiabilité de la réponse à la première question.
Souvent, deux méthodes ou sources d'informations différentes sont utilisées pour évaluer la fiabilité des mesures. Par exemple, après avoir rempli des questionnaires écrits, un certain nombre de répondants de l'échantillon initial se voient en outre poser les mêmes questions par téléphone. Sur la base de la similitude des réponses, le degré de leur fiabilité est jugé.
Parfois, sur la base des mêmes exigences, deux échantillons de répondants sont constitués et leurs réponses sont comparées pour évaluer le degré de fiabilité.
Questions à vérifier :
- Qu’est-ce que la mesure ?
- En quoi la mesure objective diffère-t-elle de la mesure subjective ?
- Décrire les quatre caractéristiques de l'échelle.
- Définir les quatre types d’échelles et indiquer les types d’informations contenues dans chacune.
- Quels sont les arguments pour et contre l’utilisation d’une gradation neutre dans une échelle symétrique ?
- Qu'est-ce qu'une échelle de Likert modifiée et quel est le lien entre l'échelle de style de vie et l'échelle différentielle sémantique ?
- Qu’est-ce que « l’effet de halo » et comment un chercheur doit-il le contrôler ?
- Quels éléments déterminent le contenu de la notion de « fiabilité des mesures » ?
- Quels inconvénients peut présenter l’échelle de mesure utilisée ?
- Quelles méthodes d'évaluation de la stabilité des mesures connaissez-vous ?
- Quelles approches connaissez-vous pour évaluer le niveau de validité des mesures ?
- En quoi la fiabilité des mesures diffère-t-elle de la validité des mesures ?
- Quand un chercheur doit-il évaluer la fiabilité et la validité d’une mesure ?
- Supposons que vous soyez engagé dans une étude de marché et que le propriétaire d'une épicerie privée vous a contacté pour vous demander de créer une image positive de ce magasin. Concevoir une échelle différentielle sémantique pour mesurer les dimensions pertinentes de l'image d'un magasin donné. Lors de l'exécution de ce travail, vous devez procéder comme suit :
UN. Organisez une séance de brainstorming pour identifier un ensemble d’indicateurs mesurables.
b. Trouvez les définitions bipolaires correspondantes.
V. Déterminez le nombre de gradations sur l’échelle.
d. Choisissez une méthode pour contrôler « l’effet de halo ». - Concevoir une échelle de mesure (justifier le choix de l'échelle, le nombre de gradations, la présence ou l'absence d'un point neutre ou d'une gradation ; demandez-vous si vous mesurez ce que vous aviez prévu de mesurer) pour les tâches suivantes :
UN. Un fabricant de jouets pour enfants veut savoir comment les enfants d'âge préscolaire réagissent au jeu vidéo « Chante avec nous », dans lequel l'enfant doit chanter avec les personnages du film d'animation.
b. Un fabricant de produits laitiers teste cinq nouvelles saveurs de yaourt et souhaite savoir comment les consommateurs évaluent les saveurs en termes de douceur, d'agrément et de richesse.
Les références
- Burns Alvin C., Bush Ronald F. Recherche marketing. New Jersey, Prentice Hall, 1995.
- Evlanov L.G. Théorie et pratique de la prise de décision. M., Économie, 1984.
- Eliseeva I.I., Yuzbashev M.M. Théorie générale de la statistique.M., Finance et Statistique, 1996.
- Cahier d'exercices d'un sociologue. M., Nauka, 1977.
Nous recommandons également
 Livraison des documents par service de messagerie comptabilité
Livraison des documents par service de messagerie comptabilité
 Inventaire des pièces jointes dans une lettre précieuse de la poste russe Exemple de remplissage d'un inventaire des pièces jointes
Inventaire des pièces jointes dans une lettre précieuse de la poste russe Exemple de remplissage d'un inventaire des pièces jointes
 Indicateurs économiques
Indicateurs économiques
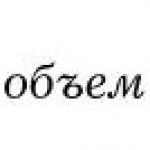 Types d'échelles utilisées dans la différentielle sémantique Exemple d'échelle différentielle sémantique
Types d'échelles utilisées dans la différentielle sémantique Exemple d'échelle différentielle sémantique
 Histoire de la Chambre russe du livre Le dernier numéro de chaque année contient un index des articles et des documents publiés dans le magazine au cours de l'année écoulée
Histoire de la Chambre russe du livre Le dernier numéro de chaque année contient un index des articles et des documents publiés dans le magazine au cours de l'année écoulée
 Jeu didactique « Lequel, lequel, lequel ?
Jeu didactique « Lequel, lequel, lequel ?